Chapter 8 Consistency in Early Vocabulary
Which words do children learn first? In spite of tremendous individual variation in rate of development (see Chapter 5; Fenson et al. 1994; Hart and Risley 1995), the first words that children utter are reported to be quite consistent. We examine this claim both qualitatively and quantitatively, focusing on the first ten words initially and then zooming out to examine this claim in typological and developmental context.
8.1 Introduction and methods
Based on the examination of diary studies, a number of early studies noted the similarities in children’s first words across languages (e.g., Clark 1973; Slobin 1970; see also Schneider, Yurovsky, and Frank 2015). This observation formed the basis for a number of theories of usage (including e.g., Clark’s influential semantic feature hypothesis). While we return briefly to the question of why we see similarity across languages in the contents of early vocabulary, in this chapter we seek to establish a firmer empirical understanding of both the similarities and differences in early-learned words across languages.
Our approach primarily follows the lead of a systematic examination of the early vocabularies of children learning English, Mandarin, and Cantonese (Tardif et al. 2008). Tardif and colleagues found that children’s first 10 words in all three languages tended to be about important people in their life (mom, dad), social routines (hi, uh oh), animals (dog, duck), and foods (milk, banana). Here we attempt to generalize this analysis, asking more broadly whether words tend to be learned in the same order across languages.
One challenge is that the precise words that children learn in different languages are (of course) language-specific. We would really like to ask whether the concepts that are being talked about are the same – or at least similar. As detailed in the Chapter 2, the items on each language’s form are adaptations and not translations: They are intended to capture the spirit of the items on the English form rather to replicate them exactly. Thus, not all words appear on all forms. In addition, conceptual mappings across languages are also subject to cross-cultural variation (the “tortilla problem” we discuss earlier). In what follows, we acknowledge this caveat, but assume for simplicity that dog, chien, and perro name (roughly) the same concept. Our approach is thus to take advantage of when translation equivalents appear on multiple forms and examine variability in how quickly these words are acquired across languages. This analysis is in some sense a “rough draft” of our more systematic quantitative approach in Chapter 10, focusing on first words specifically.
To estimate the similarity of each item’s trajectory, we use a single measure of its difficulty: age of acquisition (AoA) – the age at which 50% of children in each language are estimated to have acquired it (Appendix D). We analyzed consistency in both comprehension and production, using Words & Gestures forms to estimate age of acquisition in comprehension, and stitching across Words & Gestures and Words & Sentences forms to estimate age of acquisition in production. Because of this strategy of combining forms, we were restricted to the 29 languages for which data for both forms were available.
In total, we estimated ages of acquisition for 945 total words spread across the 29 languages. Unfortunately, not every word appeared on all forms. Figure 8.1 shows the cumulative proportion of forms on which every word appears. For our consistency analysis, we considered only the 335 words that appeared in at least 8 of the 15 languages.
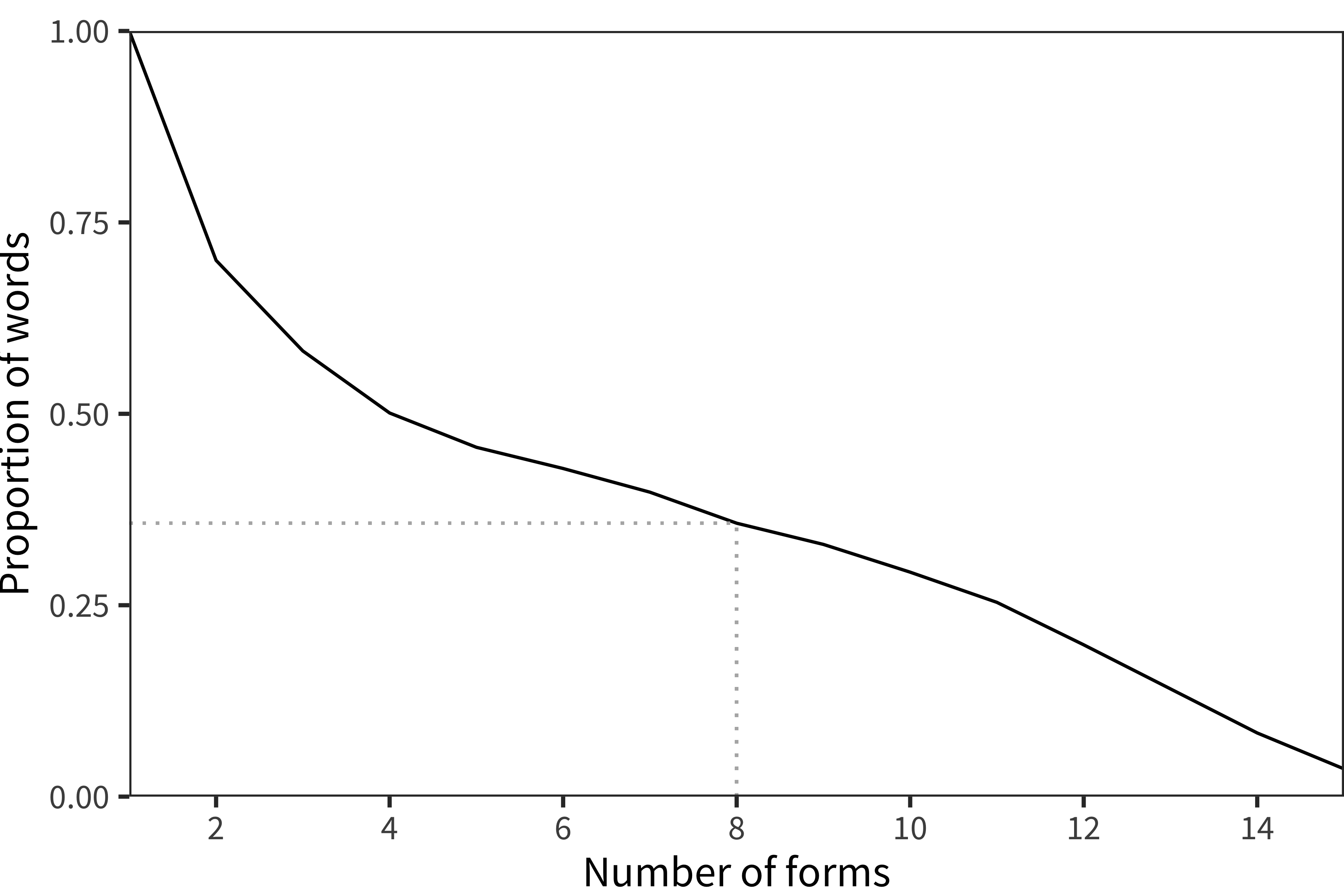
Figure 8.1: The proportion of words found on at least each of a number of languages’ CDI forms (e.g. all words appear on at least one form, 111 words appear on at least 2 forms, and so on, with 34 words appearing on all 15 languages’ forms). The dotted line shows the cutoff value we chose (8).
8.2 The first 10 words
Following Tardif et al. (2008), we begin by examining the first 10 words acquired by children across the 15 languages we measured (Tables 8.1 and 8.2). Similar words appeared in the top 10 across languages, especially in children’s earliest productions. In production, 12 of the 36 words appeared in the top ten earliest words of every language (0.33), and all but 2 appeared in at least ten languages (0.94). In comprehension, 13 of the 40 words appeared in the top ten earliest words of every language (0.32), and all but 4 appeared in at least ten languages (0.90). These words consist primarily of important family members (mommy, daddy, grandma), social routines (hi, bye, peekaboo), and sounds (yum yum, vroom, woof woof).
| mommy | hi | mommy | daddy | mommy | mommy | mommy | mommy | mommy | vroom | meow | mommy | mommy | mommy | mommy |
| daddy | woof woof | daddy | mommy | daddy | yum yum | daddy | daddy | daddy | mommy | daddy | daddy | daddy | daddy | yum yum |
| grandma | thank you | ball | baby | no | grandma | woof woof | car | peekaboo | yum yum | woof woof | woof woof | water | thank you | brother |
| bye | mommy | bye | bye | bye | vroom | grandma | cat | woof woof | hi | grandpa | grandma | yum yum | woof woof | woof woof |
| woof woof | no | hi | thank you | baby | grandpa | water | meow | cracker | daddy | aunt | vroom | woof woof | hi | baby |
| baby | bye | no | bread | ball | daddy | hi | motorcycle | water | bye | mommy | food | bread | peekaboo | vroom |
| no | daddy | dog | peekaboo | vroom | banana | grandpa | baby | baby | thank you | grandma | yum yum | no | drawer | bye |
| yes | vroom | baby | ball | sock | this | meow | bug | yes | woof woof | bye | bye | bye | meow | water |
| grandpa | yes | woof woof | sock | peekaboo | bye | no | banana | ball | yes | cereal | dog | baby | moo | ball |
| aunt | food | banana | shoe | moo | car | shoe | baa baa | no | peekaboo | ball | car | yes | no | doll |
| grandma | daddy | bottle | no | milk | yum yum | mommy | baa baa | food | child’s name | yum yum | woof woof | yum yum | child’s name | water |
| mommy | child’s name | daddy | mommy | mommy | cat | daddy | meow | daddy | mommy | meow | yum yum | water | mommy | ball |
| bye | mommy | mommy | daddy | daddy | doll | peekaboo | car | mommy | daddy | cat | dog | milk | daddy | up |
| daddy | peekaboo | child’s name | peekaboo | child’s name | balloon | child’s name | bug | peekaboo | bye | eye | car | mommy | peekaboo | yum yum |
| peekaboo | yum yum | bye | bye | bye | ball | hi | cat | no | hi | daddy | ball | daddy | bye | peekaboo |
| vroom | no | no | bath | peekaboo | head | woof woof | doll | dirty | peekaboo | grandma | food | bye | bath | mommy |
| grandpa | bye | peekaboo | hi | no | light | dog | ball | bath | no | grandpa | pacifier | no | hi | daddy |
| cat | hi | hi | good night | bathtub | daddy | water | milk | ball | yum yum | hi | mommy | woof woof | lamp | child’s name |
| child’s name | woof woof | dog | yes | bath | mommy | bottle | medicine | cracker | good night | woof woof | daddy | dog | grandma | bye |
| woof woof | ball | ball | meow | ball | grandpa | grandma | spoon | water | grandma | dog | grandma | cookie | no | bottle |
Strongly ratifying the conclusions of Tardif et al. (2009), similar words appeared in the top 10 across languages. Similarities were especially prominent in children’s earliest productions. These words consist primarily of important family members (mommy, daddy, grandma), social routines (hi, bye, peekaboo), and sounds (yum yum, vroom, woof woof).
Unfortunately, we cannot determine if the greater consistency found in early production is a real regularity about children’s lexical development, or is instead a measurement artifact arising from the greater difficulty of reporting on a child’s comprehension (see Chapter 4).17 It may be that early communicative needs drive the first words children produce to be even more similar than the first words they comprehend.
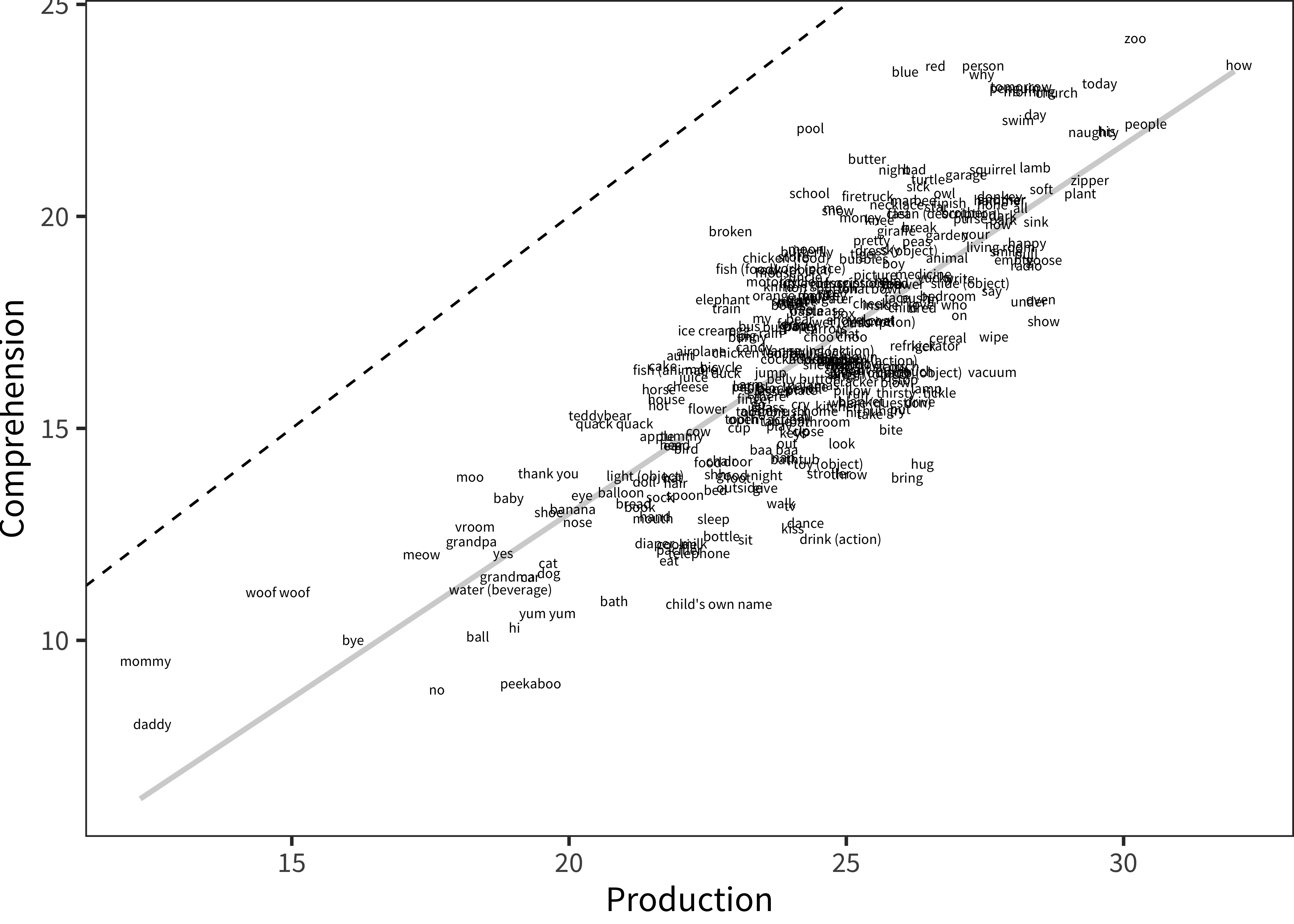
Figure 8.2: Average age of acquisition in comprehension and production for each measured word. Dashed line provides a reference with slope = 1 (identical age of acquisition).
Despite these differences between comprehension and production, words that are reported to be acquired early in one measure are also generally reported to be acquired early in the other. Figure 8.2 shows the relationship between the mean age of acquisition in production and the mean age of acquisition in comprehension for each of these 335 words across the 15 languages. The correlation between the two measures was quite high: r = 0.80 (p < 0.001). Thus, apparent inconsistencies in first words for comprehension may be more a function of measurement errors in comprehension than any systematic difference.
Taken together, these analyses suggest that children’s earliest words, and by inference the processes that underpin them, are highly similar across languages. The source of this similarity is hard to pin down, however. One possibility is that the difficulty of learning a word is determined predominantly by the complexity of the concept denoted by that word, and thus that variability in linguistic (e.g., phonological and syntactic complexity) and cultural (e.g., styles of parental interaction with children) features play a relatively small role in determining the difficulty of learning a word (Gentner and Boroditsky 2001). Alternatively, the primary driver of difficulty could be linguistic, but the dimensions of linguistic variability could be orthogonal to the difficulty of learning. For instance, verbs may be more difficult than nouns because they are relational, and thus learning nouns makes learning verbs relatively easier than learning verbs makes learning nouns (Gleitman 1990). In this case, the linguistically relevant dimensions would be relatively invariant across languages (Snedeker, Geren, and Shafto 2007). Finally, it is worth noting that because the words on the CDI are not a random sample of words in each language, these correlations may overestimate the degree of cross-linguistic similarity, even though they are consistent with earlier diary studies.
In Chapter 10 we begin to take up these questions using predictive models. Prior to taking this step, however we consider cross-linguistic ordering more holistically. In the remainder of the chapter, we address this problem from two directions: (1) Is similarity in order of acquisition for two languages related to the degree of similarity between the two languages, and (2) Does similarity in order of acquisition change over development?
8.3 Acquisition similarity and linguistic similarity
Unfortunately, the 15 languages in our analyses are both a small and non-representative sample of the world’s languages, and thus do not have sufficient power to detect typological features of language that might be responsible for differences in the similarity of acquisition across languages (Piantadosi and Gibson 2014). Nonetheless, the languages do come from different languages families, and do vary in their phylogenetic distance. We leverage this variability to ask whether the similarity between two languages is related to similarity in how quickly words for the same concepts are learned in those two languages.
Instead of correlating the average similarity of age of acquisition across all languages, we consider the pairwise similarities in the age of acquisition of each of the 335 words in each language. Figure 8.3 shows these pairwise correlations for production as a matrix in which each cell shows a single pairwise correlation. This correlation matrix appears to contain a significant amount of structure, with languages that are from the same language family (e.g. Norwegian and Danish) showing higher correlations in their ages of acquisition for the same concepts. Perhaps unsurprisingly from the high average correlation between production and comprehension, pairwise correlations were nearly identical for production and comprehension (r = 0.98, p < 0.001); we omit the comprehension matrices for length. Figure 8.4 shows a dendrogram produced by hierarchically clustering these pairwise correlations.
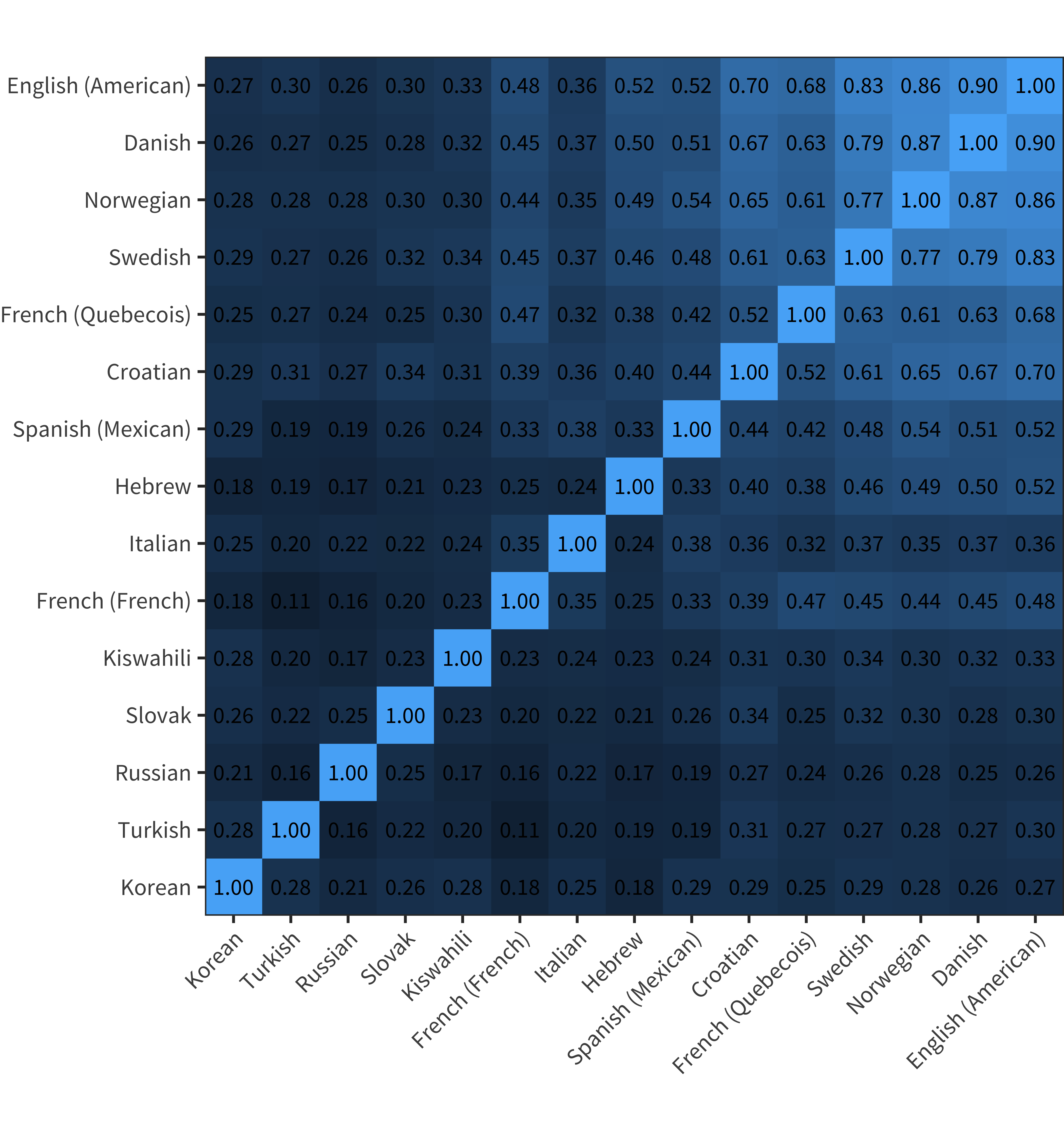
Figure 8.3: Correlation matrix showing pairwise correlations in words’ age of acquisition. Languages that are more similar have more similar acquisition orders.
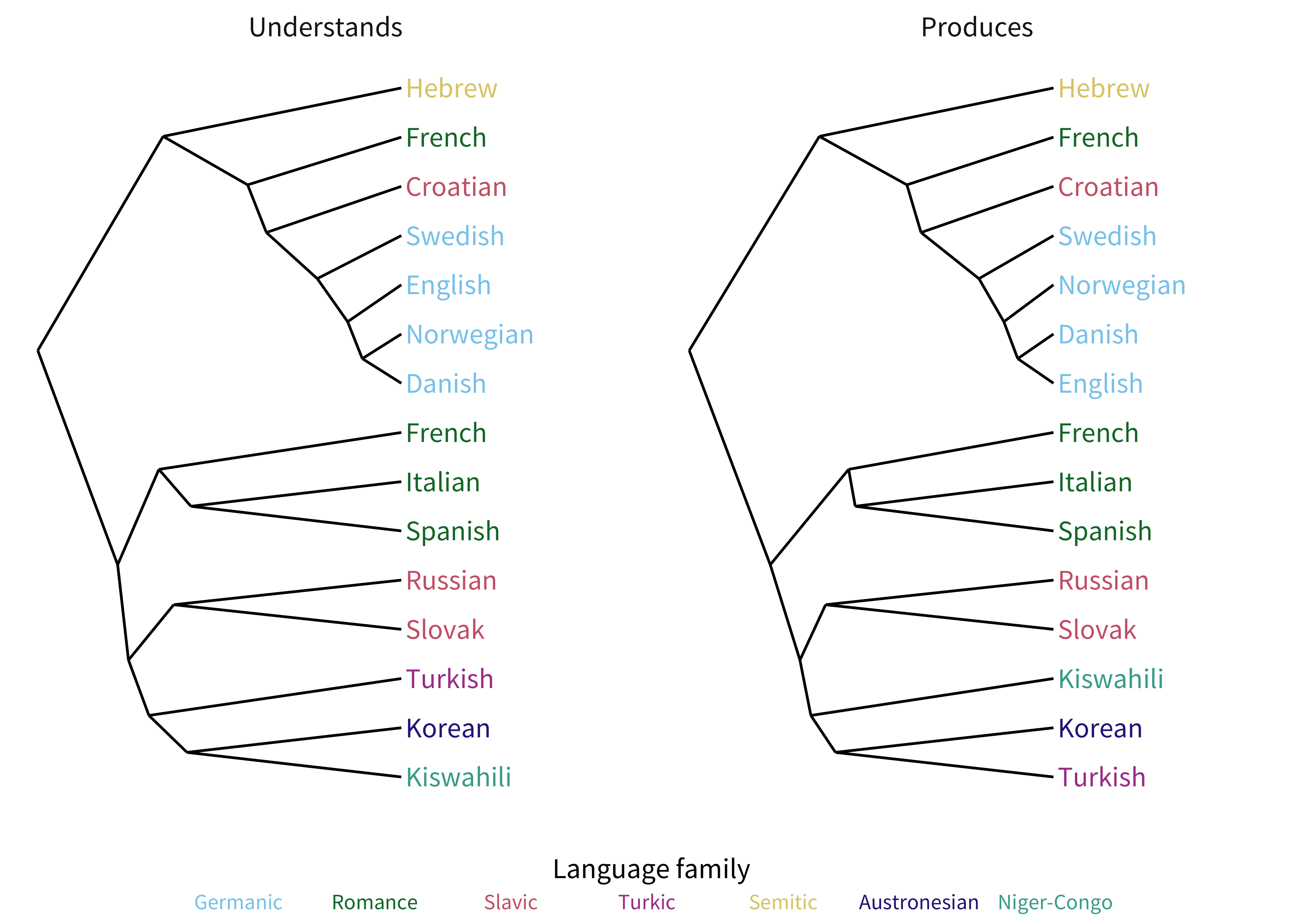
Figure 8.4: Dendrograms of the similarity in the ages of words’ first production cross-linguistically.
These dendrograms show high similarity within the North Germanic, Slavic, and Romance language families. Some relationships resist straightforward linguistic explanations (e.g., the relationship of Quebec French to other languages). These may be due to non-uniform sparsity of data across these languages, or may instead reflect interesting cultural or other sources of variability. Despite these cases, the order in which words are acquired appears to a high degree to reflect the structure of the languages that children learning these words speak. To confirm this observation quantitatively, we borrowed an established measure for measuring linguistic similarity: the lexical similarity of words for the same meaning (Wichmann et al. 2010).
Using a set of 40 words for meanings common to all of the words languages, Holman et al. (2008) were able to use a string-edit distance metric to recover linguistic similarity estimates that correlated highly with geographic distance and also several typological systems. This method is appealing for our purposes as it is relatively agnostic as to the processes of language contact and change that have produced modern-day languages and instead tracks the similarity of word forms themselves. The language distance measures produced by this method were highly correlated with pairwise correlations in acquisition trajectories for both production (r = –0.44, p < 0.001) and comprehension (r = –0.41, p < 0.001).
We also applied this same analysis to the words on the CDI themselves. For each language, we computed the average normalized Levenshtein (1966) distance between words for each of the 335 common words in our analyses.18 This measure was even more highly correlated with pairwise acquisition trajectories than similarity computed using the 40 words identified by Holman et al. (2008), with relatively high correlations for both production (r = –0.57, p < 0.001) and comprehension (r = –0.52, p < 0.001).
Because this analysis likely overestimates the dissimilarity of languages written in different scripts – as every word receives a normalized Levenshtein distance of 1 in this case – we replicated this analysis at the phonemic level. We used eSpeak to compute phonetic transcripts of each word and repeated the same analysis on distance between words’ phonetic units in the International Phonetic Alphabet (IPA; Decker and others 1999). These correlations between IPA distance and pairwise age of acquisition trajectories were again reliable although slightly attenuated for both production (r = –0.29, p = 0.01) and comprehension (r = –0.26, p = 0.02). The robustness of these correlations across a variety of methods suggests that in addition to the high degree of general cross-linguistic similarities in the order of acquisition of words, the dissimilarities between them likely reflect differences in the wordforms of the target languages being learned.
Because the languages we studied here are far from a reliable, representative sample of the world’s languages, the correlation between linguistic similarity and acquisition order similarity is hard to interpret definitively (Naroll 1965). Languages in which word forms are similar are also likely to have similar cultural beliefs around parenting, similar household organization and incomes, and generally share other non-linguistic features in common. Nonetheless, these analyses suggest that in addition to early communicative need – which may be quite similar cross-linguistically – language and culture-specific features govern the order of acquisition. In the following section, we take on the the relationship between early communicative need and linguistic variability directly, asking whether acquisition orders are equally cross-linguistically similar over development, or whether they instead diverge or converge as children learn more words.
8.4 Consistency across development
In the next analysis, we ask whether similarities in ages of acquisition are constant over the course of acquisition, or whether the similarity across languages changes over development. If variability in acquisition trajectories across languages reflects variability in those languages, we might expect that children’s trajectories diverge over the course of language acquisition as the structure of their target language or their cultural milieu play a stronger role in guiding which words are easy or important to learn. Put more simply: our analyses of the first 10 words above shows striking similarity in the earliest words. Does this similarity decrease for the next 300 words?
In order to measure change in cross-linguistic consistency over development, we extend the age of acquisition-correlation approach we have used throughout this chapter. For each concept that appeared in at least 8 languages, we computed its average age of acquisition across all languages in whose CDIs it appeared in both comprehension and production. We then ordered these words from the earliest learned word on average (mommy to the latest learned word how). We then computed the average cross-linguistic correlation in age of acquisition for the increasingly-large sets of words starting with 5 words to 335 words. If the correlation increases over acquisition, we can infer that acquisition trajectories become more similar as more words are learned, that is, the hardest to learn words are learned more similarly across languages. In contrast, if the correlation decreases, we can infer that children start out learning similar concepts regardless of their native language, but that linguistic and cultural variability plays a greater role in the learning of later words.
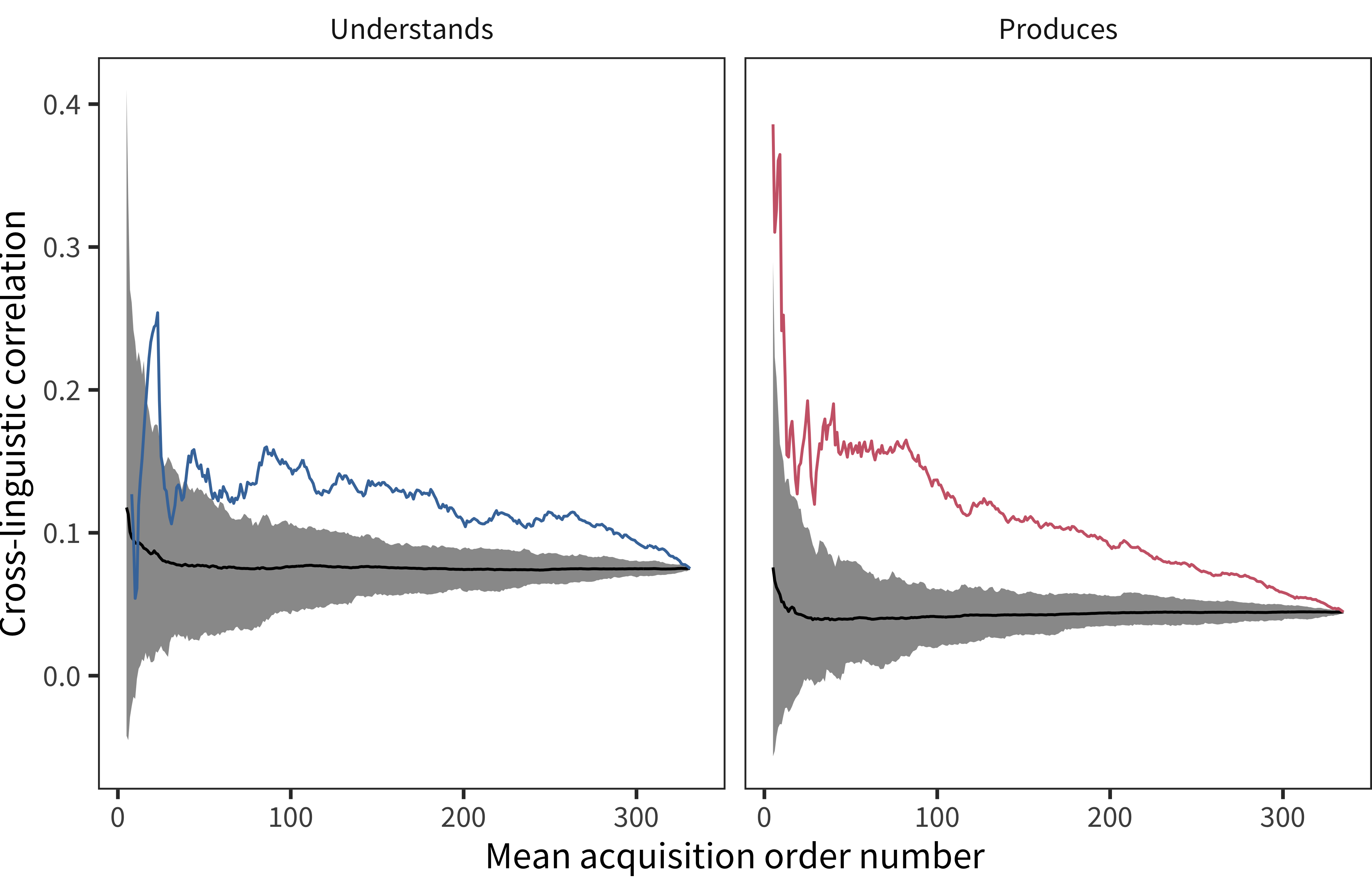
Figure 8.5: Cross-linguistic correlation ages of words’ acquisition over the course of language development. Colored lines show empirical correlations, the gray area shows a 95 percent confidence interval for a randomly shuffled baseline. Especially in production, cross-linguistic similarity declines over the course of language development.
Figure 8.5 shows these correlations for both comprehension and production over the course of acquisition. In addition, the gray shaded region shows a 95% confidence interval for a random baseline in which the concepts were ordered randomly, rather than in average acquisition order. This baseline is important to control for changes in measurement error that arise from changing numbers of concepts in the correlation. For both comprehension and production, the trajectories are reliably above the shuffled baseline. This trend is much more apparent for the earliest words in production, mirroring our qualitative sense from the analysis of the first 10 words above. Further, both trajectories clearly decrease over the course of acquisition.
These results confirm that there is substantially more similarity in the earliest learned words than in later learned words cross-linguistically, especially in production. This pattern of results is consistent with an account in which cross-linguistically shared communicative needs are a strong driver of the earliest acquired words. After these needs are met by the initial vocabulary, language-specific factors factors – variability in the forms, frequencies, and contexts of use for words – may play a larger role in the order of children’s acquisition.
8.5 Conclusions
Children in all languages and culture learn language, but the languages they learn vary, and the cultures into which they are born may have quite different cultural practices around both language and cognitive development. Nonetheless, the order in which children learn the word for specific concepts in their own language shows a substantial degree of cross-linguistic similarity. Further, dissimilarities are well-explained by measurable linguistic dissimilarity. This cross-linguistic similarity in concepts decreases over the course of acquisition. While the first ten words acquired in each language were highly consistent, later words were substantially more different.
As we noted in the introduction, the general observation of cross-linguistic similarity in early vocabulary has been taken as evidence for a wide variety of different theoretical claims. Our view is that these results indicate a shared core of concepts – e.g., social routines, important people, and some early foods and household animals – that are perhaps especially important for communication independent of their linguistic realization.
We acknowledge, however, that there are likely many reasons for consistency of early words. One intriguing suggestion is that the phonological forms of words used with children actually evolve (or are adapted by parents) to be easier for children to say. One version of this hypothesis comes from Jakobson (1962), who hypothesized that parents adapt the word forms for mother and father to be easy for children to say or even to babble. Thus, the sound convergence across languages in the forms of words for these concepts (which is quite substantial) is due to convergence in what sounds are easy for children to say. This same mechanism could operate over other important early vocabulary as well, though note that this account already presupposes some notion of cognitive importance!
Regardless of the precise reason for this phenomenon, the similarity in early vocabulary is undeniable (ratifying suggestions by Clark 1973 and others). As acquisition unfolds, however, the features that make languages (and cultures) different from one another play an ever increasing role in driving vocabulary development. In Chapter 9, we explore demographic differences in acquisition that help to explain why two children learning the same language may acquire different words at different rates.
This finding is prima facie inconsistent with another recent analysis comparing variability in comprehension and production vocabularies (Mayor and Plunkett 2014). This analysis noted that comprehension vocabularies tend to be less idiosyncratic across children – rather than across languages – than production vocabularies.↩︎
Levenshtein distance is a measure of the minimum number of insertions, deletions, or substitutions required to transform one string into another. For instance, the distance between the Italian and Norwegian words for dog (cane and hund) is 3. We computed this measure pairwise for all words, and then divided it by the number of characters in the longest word in order to get the edit distance per character (0.75 for cane and hund).↩︎