Chapter 11 Vocabulary Composition: Syntactic Categories
- Note:
- An earlier version of this work was presented at the Boston University Conference on Language Development in 2015.
We have previously examined vocabulary with a wide angle lens, focusing on total vocabulary size (Chapter 5), as well as with a narrower lens, examining individual words (Chapter 10). Here we take a middle perspective, splitting vocabulary by syntactic category and analyzing consistency and variability across languages in the acquisition of these categories. A primary goal of this analysis is to quantify the “noun bias” across languages. In addition, we quantify the degree of bias for or against verbs and closed-class words. This chapter deals primarily with the aggregate biases for or against syntactic categories across entire datasets, but in Chapter 15, we consider variation of this sort within individuals.
11.1 Introduction
11.1.1 The composition of early vocabulary
As we reviewed in Chapter 8, the first words children utter are quite consistent and primarily composed of names for people and things and words related to social routines (see also Tardif et al. 2008; Schneider, Yurovsky, and Frank 2015). Soon after, however, they begin to add predicates, such as verbs (go) and adjectives (pretty), in greater proportions than earlier in development and may even begin to use closed-class forms, such as determiners (the). These patterns seem to suggest a developmental course that follows distinct “waves” of learning for words from different classes. That is, along with early social routines, nouns tend to predominate early vocabularies, while other types of words, such as predicates and closed class forms, are learned later. This pattern may be further qualified by differences in the types of words learned in comprehension vs. production (Benedict 1979).
Examination of the composition of early vocabulary is complicated by the fact that we categorize words by their adult syntactic category. We do so in the discussion below without presupposing that children themselves do this categorization, however (Tomasello 2000). Children may be sensitive to these categories very early in development (Valian 1986; Yang 2013) or they may discover them either gradually (Pine and Lieven 1997) or more quickly (Meylan et al. 2017). Importantly, though, we treat adult syntactic categories as an analytic convenience that describes certain regularities in how groups of words are distributed in the talk by adults (as captured, for example, in language samples) and how they function in different contexts, rather than as an ontological fact about children’s knowledge.
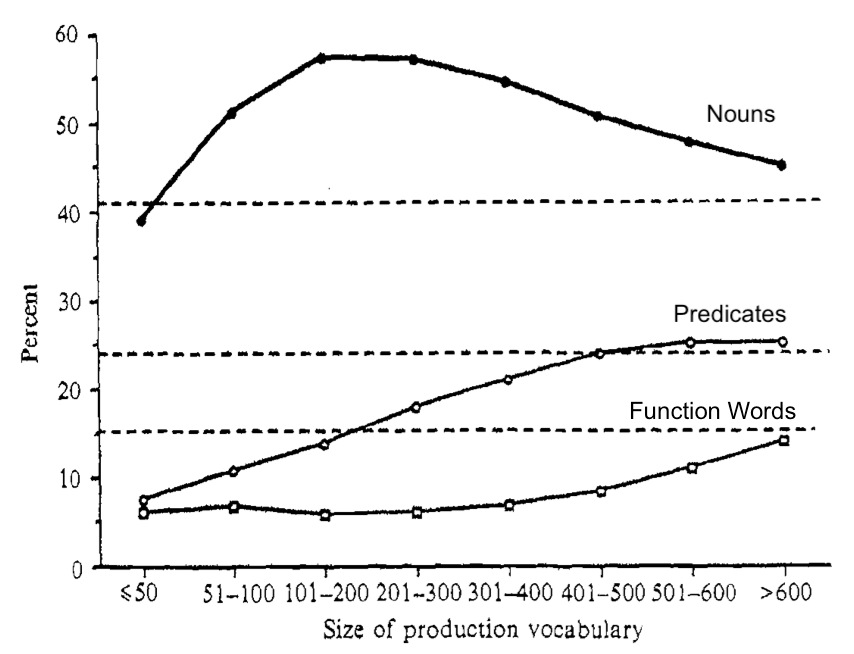
Figure 11.1: Figure 1 from Bates et al. (1994), showing developmental trends in the categorical composition of early vocabulary as number of items. Horizontal lines represent the number of opportunities on the vocabulary checklist for each category.
Bates et al. (1994) characterized these patterns of vocabulary composition in the following way. Figure 11.1 (reprinted from that paper) shows average vocabulary composition of nominals, predicates and closed class forms as a function of children’s vocabulary size for English-speaking children from the original CDI WS norming study (Fenson et al. 1994). Note that when children only know a few words (e.g., fewer than 50), nominals comprise the greatest proportion of the words that children are reported to produce, with very few predicates or closed class forms (<10%). As the children learn the next hundred words or so, the proportion of nominals increases even more dramatically with a gradual increase in the proportion of children’s vocabularies that are predicates. Closed class forms remain a much smaller proportion over this period. Yet, after about 300 words, children do not appear to add nouns to their vocabularies at the same pace that they did earlier in development; consequently, the proportion of nominals tends to decrease.20 During this developmental period, the proportion of predicates in the vocabulary tends to increase, followed by growth in the proportion of closed class forms.
A different way to capture these same trends is shown in Figure 11.2 (also reprinted from Bates et al. 1994). Here, each of the categories of words is plotted as a proportion of the opportunities on the checklist, again as a function of total vocabulary size. Shown in this way, the curves reflect when in development children are reported to produce half of the words in each of the categories, as represented by the solid horizontal line. For example, it is easy to see that 50% of the nouns have been checked (on average) when total vocabulary is between 200 to 300 words, whereas, 50% of the predicates are reported (on average) when overall vocabulary size falls between 300 and 450 words. Finally, closed-class opportunities do not reach the 50% mark until total vocabulary falls between 500 and 600 words.
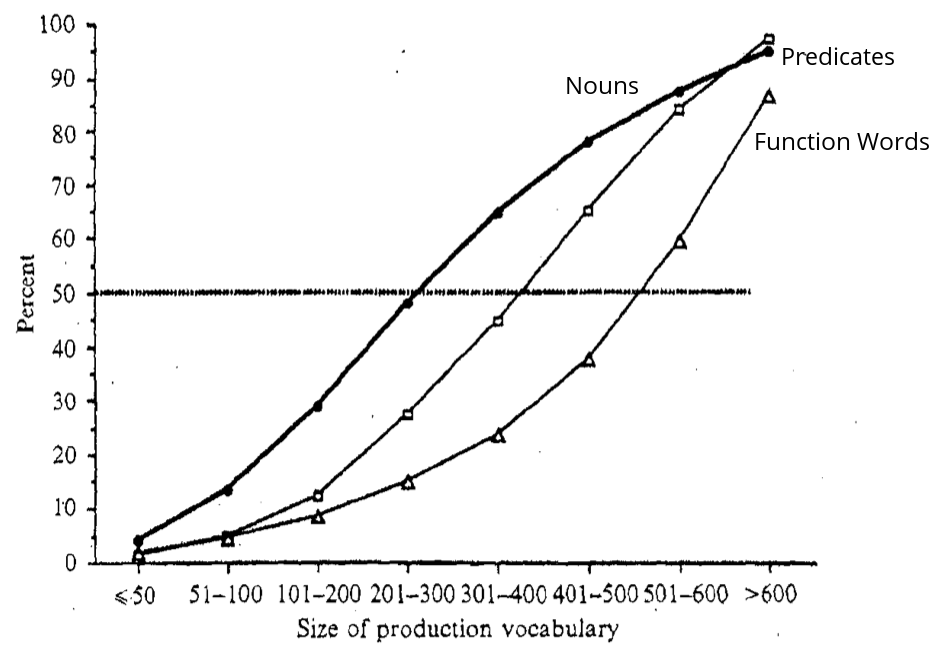
Figure 11.2: Figure 3 adapted from Bates et al. (1994), showing developmental trends in the categorical composition of early vocabulary, using proportions of total opportunities in each category. Horizontal line represents the point at which 50% of the items are chosen on average for each category.
11.1.2 The noun bias
Why do children learn nouns before verbs and other types of words? This question has received a great deal of attention in the literature; we briefly summarize some of the major issues here. Before doing so, we note that Bates et al. (1994) consider the contrast between nouns and predicates, while other literature considers verbs specifically rather than grouping predicates together (e.g., Gentner 1982). In the analysis below, we split the difference by beginning with predicates (to increase the amount of data we consider) and later breaking down that category into verbs and adjectives.
One reason for the widely-reported “noun bias” (over-representation compared with verbs and predicates more generally) could be that nouns are simply more frequent in the talk to young children. It is well-established that children learn the words that they hear more often (e.g., Hart and Risley 1995). Many observational studies of English-speaking caregivers have demonstrated that caregivers use more nouns than verbs (in both types and tokens) with their children (e.g., Fernald and Morikawa 1993; Goldfield 1993; Gopnik, Choi, and Baumberger 1996; Kim, McGregor, and Thompson 2000; Poulin-Dubois, Graham, and Sippola 1995; Tardif, Shatz, and Naigles 1997). Gentner (1982) considered and rejected this explanation, however: Predicates and function words are often more frequent than nouns, not less, thus pure frequency is not a sufficient explanation of the phenomenon. We investigated the role of word frequency in more detail in Chapter 10; our findings are consistent with Gentner’s.
Other researchers have framed the “noun bias” in terms of universals about what and how different words “partition” things (e.g., objects, people, relations, qualities, etc.) in the world. For example, Gentner (1982) argued that children learn nouns before verbs because the meanings of nouns are easier to encode since they identify things that can be more easily differentiated in the world (e.g., common everyday objects). Verbs and other predicates, in contrast, express relations among things in the world. Hence, the meanings of verbs are less accessible to children through common, everyday experiences and thus, are more difficult to map onto word forms without additional linguistic or social support. In addition, verbs and predicates may be more likely to vary in their precise meaning across languages.
Another reason that nouns might be easier than verbs for young children is that nouns tend to be less morphologically complex than verbs (e.g., Tardif, Shatz, and Naigles 1997). For example, in many languages, nouns are typically marked for number, case, and gender, while verbs are likely to additionally carry tense information. In English, at least, verbs might also be harder to learn because they tend to occur in sentence-medial position (rather than sentence final), which make verbs less salient in the input that children hear (Slobin 1985; Caselli et al. 1995).
Finally, differences in children’s acquisition of nouns vs. verbs might result from differences in the contexts in which children hear nouns vs. verbs in the speech from caregivers (e.g., Choi and Gopnik 1995; Tardif, Gelman, and Xu 1999). Several researchers have examined what caregivers talk about using naturalistic data of caregiver-child interactions. For example, caregivers in some cultures tend to emphasize the names for people or things in the world, spending a great deal of time providing labels and “names for things” for their children. In other cultures, caregivers do so much less frequently, instead focusing on the actions in which those objects or people engage (e.g., Fernald and Morikawa 1993; Gopnik, Choi, and Baumberger 1996). These differences in input to children could influence which words are salient for children, and hence, which words they are most likely to learn.
What is the evidence that a noun bias is a universal feature of children’s vocabularies? Documenting the extent to which the noun bias is universal is relevant to understanding mechanisms of language learning, in particular, the presence of conceptual biases in early acquisition and the role of cross-cultural variability in the input that children receive from caregivers. Some studies find consistent evidence for a noun bias in English, as well as in Korean and Italian (Bates et al. 1994; Au, Dapretto, and Song 1994; Caselli et al. 1995; Kim, McGregor, and Thompson 2000). The literature is mixed, however, and other studies do not find evidence of a noun bias in languages as varied as French, German, Chinese, Estonian, and Korean (Bassano 2000; Bloom, Tinker, and Margulis 1993; Choi and Gopnik 1995; Kauschke and Hofmeister 2002; Tardif 1996; Tardif, Gelman, and Xu 1999; Schults and Tulviste 2016).
Identifying the extent of cross-linguistic variation vs. universals with respect to the noun bias has been difficult, however, since variation across studies may be due to the different methodologies that are used. Even within a single language – Korean – parent reports of children’s first words find a noun bias (e.g., Au, Dapretto, and Song 1994), whereas studies using direct observational methods find less evidence for this pattern (e.g., Gopnik, Choi, and Baumberger 1996). Few studies have had the scope to directly compare the extent of the noun bias across multiple languages using a common methodology.
One notable exception in a literature where samples have been small – in terms of both languages and children – is Bornstein et al. (2004), in which the researchers compared vocabulary composition in seven languages. In this chapter, we follow their comparative approach (see also Tardif et al. 2008). Since we have access to many more observations, our approach offers a more comprehensive approach than these earlier studies. Moreover, we attempt to quantify the estimates of the extent to which languages show a noun bias: we develop a statistical method for quantifying the extent of the noun bias across the entire developmental range in which a particular form is used.
11.2 Methods and data
Each CDI form contains a range of words from different syntactic categories. As in Chapter 10, we adopt the categorization of Bates et al. (1994), categorizing words into nouns; predicates (verbs, adjectives, and adverbs); and function words (also referred to as “closed class” words). For each child’s vocabulary, we compute the proportion of the words in each of these categories that they are reported to produce. Following the approach developed by Bates et al. (1994), for each of the languages in our sample, we plot these proportions against total vocabulary. We use a style similar to Figure 11.2, with some modifications; our version of this plot is shown schematically in Figure 11.3. Taking nouns as our example, if a child learns words irrespective of syntactic category, then the proportion of nouns in the child’s vocabulary should be the same on average as the proportion of total vocabulary that the child knows (the diagonal). In contrast, if the child learns more nouns than expected, their datapoint would be above the diagonal; if they learn fewer, their datapoint would fall below the diagonal. By averaging these datapoints, we can then assess the average bias for or against nouns (and other categories as well).
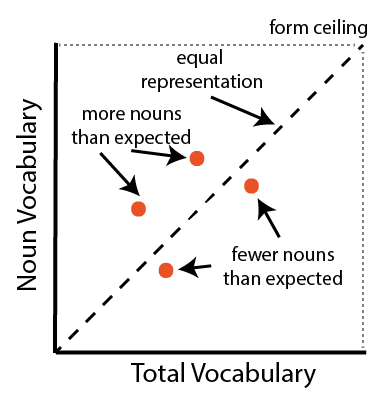
Figure 11.3: Schematic of our vocabulary composition analysis.
In this chapter, we limit our analysis to traditional WS and WG forms (along with variants in these classes) because short forms, like the one used in the British English TEDS study, do not typically include category information. We also exclude longitudinal administrations so as not to over-weight particular children in our estimates of the extent of category biases in the population.
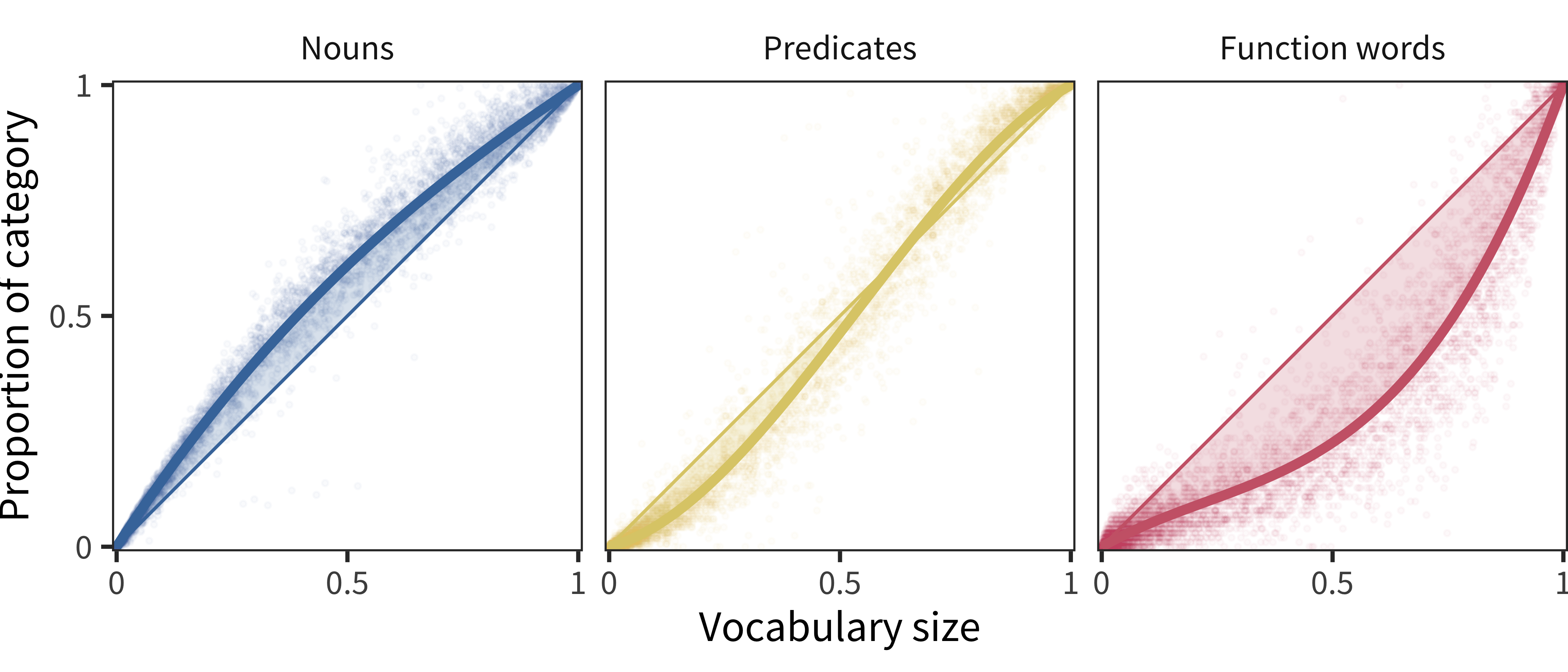
Figure 11.4: For American English WS data, proportion of each lexical category produced by each child as a function of the proportion of all vocabulary items produced by that child. Lines show model fits.
Figure 11.4 shows this analysis for the American English WS data. Each point shows an individual child’s vocabulary, and each panel shows a different lexical class (thus each child is represented once in each panel). The curves show the relationship between a class and the whole vocabulary. We capture the overall trend in this plot by estimating a generalized linear model over the data, predicting category proportion as a function of total production (shown by the thick lines). This model is fit with third-order polynomials (to allow both concave and convex functions, and changes in convexity). We fit these models with the constraint that they must predict the point (x = 1, y = 1), so that they are guaranteed to arrive at the diagonal point in the special case that all words on a form are checked.21
The final step in our method is to capture the overall bias in a particular sample by estimating the difference in area between the curve and the diagonal. If the curve is substantially above the diagonal, this difference will be positive (indicating e.g., a positive noun bias). In contrast, if the curve is below the diagonal, the difference will be negative. To capture uncertainty in this area estimate, we conduct a resampling analysis where we randomly resample each population of children 1000 times with replacement, then recompute the area measurement. Confidence intervals displayed below are based on this resampling procedure.
Critically, this analysis controls for a number of confounds in previous analyses. First, because our interest is in the shape of the overall curve, under-representation of children in some age-band should add uncertainty but not bias. Of course, if data are too sparse, estimates will be unconstrained (visible in wide confidence intervals), but particulars of age sampling should not bias our estimates. Second, in principle, the analysis should not be biased by the number of items in a particular category, as the analysis is relative to the numerical representation of a particular class on the form. Thus we should be able to compare across forms with larger or smaller numbers of items in particular sections.
11.3 Results
We present results of this analysis across languages, beginning with comprehension for WG-type forms and moving to production for WS-type forms. We do not analyze WG production data here, however. For the most part, production estimates on WG forms are quite low, and hence curves are relatively unconstrained (or determined by a small number of children who are reported to have very large early vocabulary sizes).
11.3.1 Comprehension (WG)
Figure 11.5: For each language’s comprehension data, proportion of each lexical category produced by each child as a function of the proportion of all vocabulary items produced by that child. Lines show model fits.
Comprehension results are shown in Figure 11.5. This representation of the data is the most complete, but it can be somewhat overwhelming. The largest trend visible in these plots is the highly-consistent under-representation of function words. In contrast, though most theoretical discussion has centered on nouns and predicates, these two categories appear quite close to one another in most languages. For further detailed comparison, we show summaries of curve areas for each language in Figure 11.6.
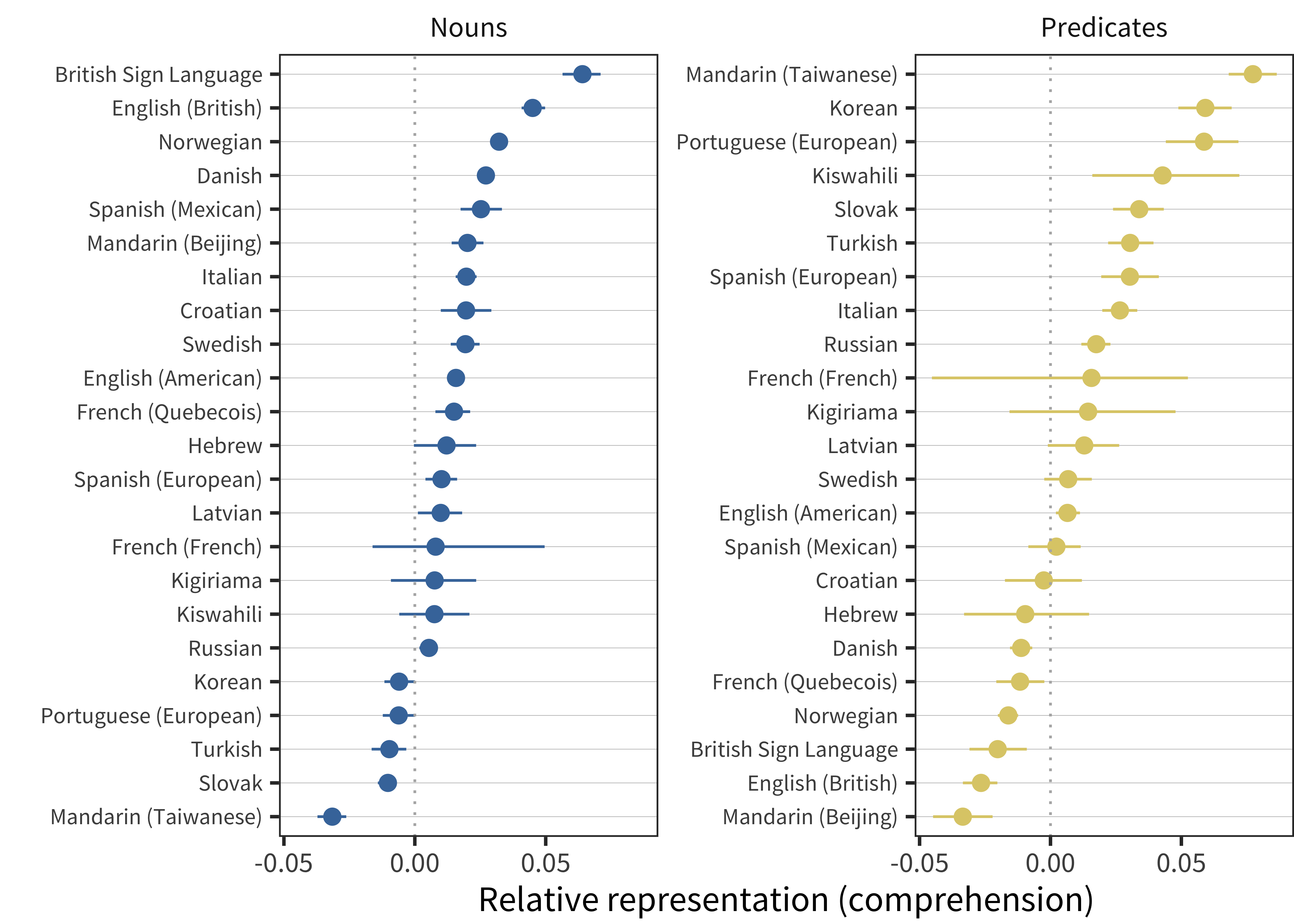
Figure 11.6: Relative representation in vocabulary compared to chance for nouns and predicates for comprehension data in each language (line ranges indicate bootstrapped 95% confidence intervals).
Nouns are over-represented in many – but not all – languages. Mandarin, Slovak, Turkish, Portuguese, and Korean, a set of typologically- and culturally-distinct languages, show slight under-representation, with British Sign Language and British English showing the largest over-representation of nouns. Predicates are under-represented in some datasets and over-represented in others. Even datasets that are very closely related (e.g., Taiwanese Mandarin and Beijing Mandarin) show substantial differences in the degree of predicate bias. Confirming the visual impression of a tradeoff between nouns and predicates, there is a very strong negative correlation between noun and predicate bias measures (r(21) = –0.82); this correlation should be interpreted with some caution as nouns + predicates + function words are constrained to sum to 1, so some degree of correlation is assured.
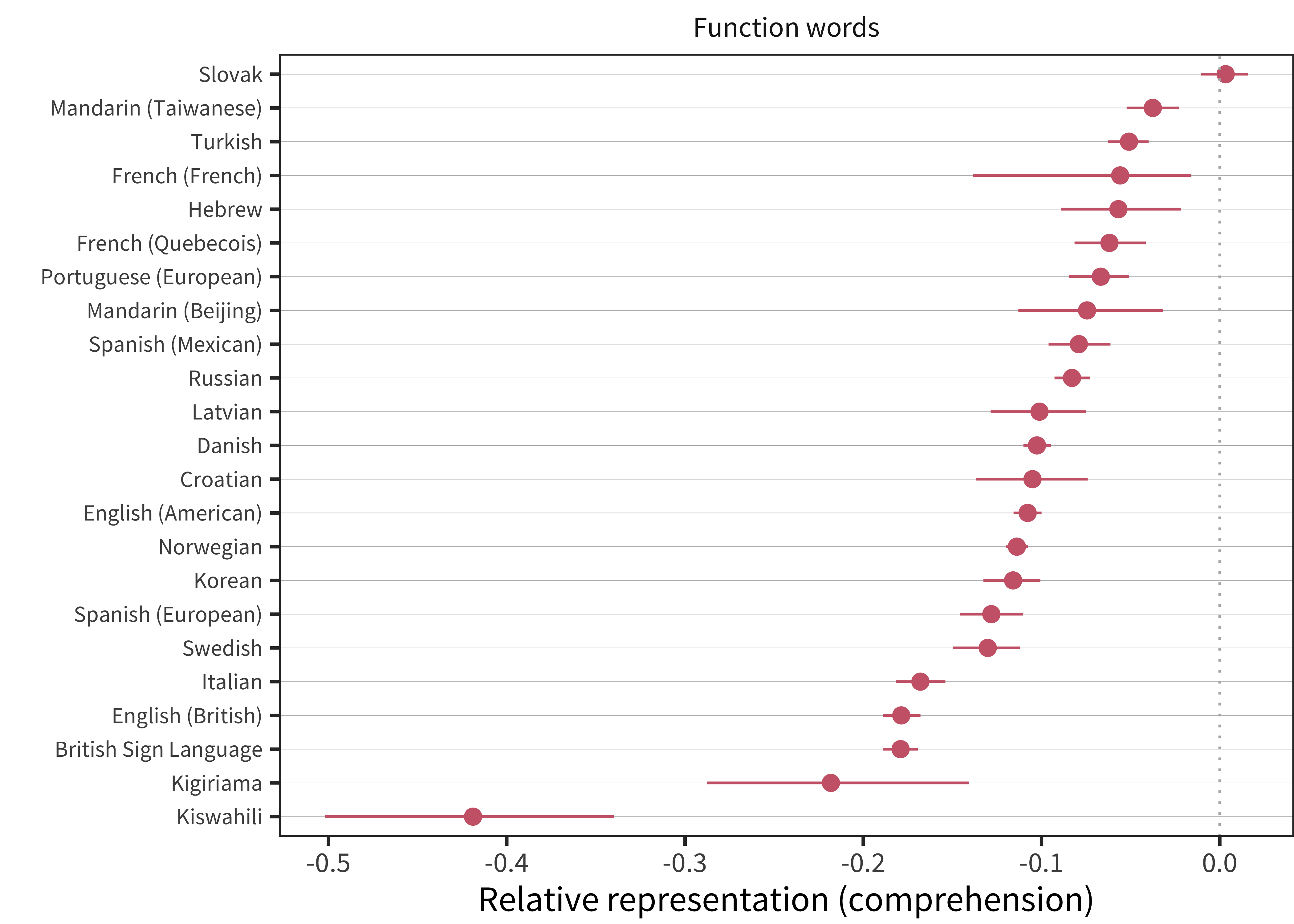
Figure 11.7: Relative representation in vocabulary compared to chance for function words for comprehension data in each language (line ranges indicate bootstrapped 95% confidence intervals).
Function words are substantially under-represented across nearly every language and dataset in our sample (except Slovak). The scale difference on this plot should also be noted – function-word bias values are far more extreme than noun and predicate bias values. These results likely reflect some combination of true under-representation of function-words as well as the difficulty of reporting on function-word comprehension in very early language (see Chapter 4 for more details on this issue). Such issues may also vary across cultures, languages, and administration methods. Function-word representation might plausibly differ due to linguistic factors such as morphological complexity, pronoun dropping, agreement, etc. However, it is also notable that the two lowest function-word scores come from Kiswahili and Kigiriama (Alcock et al. 2015), a study in which the predominantly rural, low-education parents may have had substantially less meta-linguistic awareness.
11.3.2 Production (WS)
Figure 11.8: For each language’s production data, proportion of each lexical category produced by each child as a function of the proportion of all vocabulary items produced by that child. Lines show model fits.
We next turn to production data from WS-type forms (Figure 11.8). We can immediately see the same trend in the under-representation of function words as we observed in comprehension. In addition, however, in many but not all languages, a noun bias is more evident than it was in comprehension.
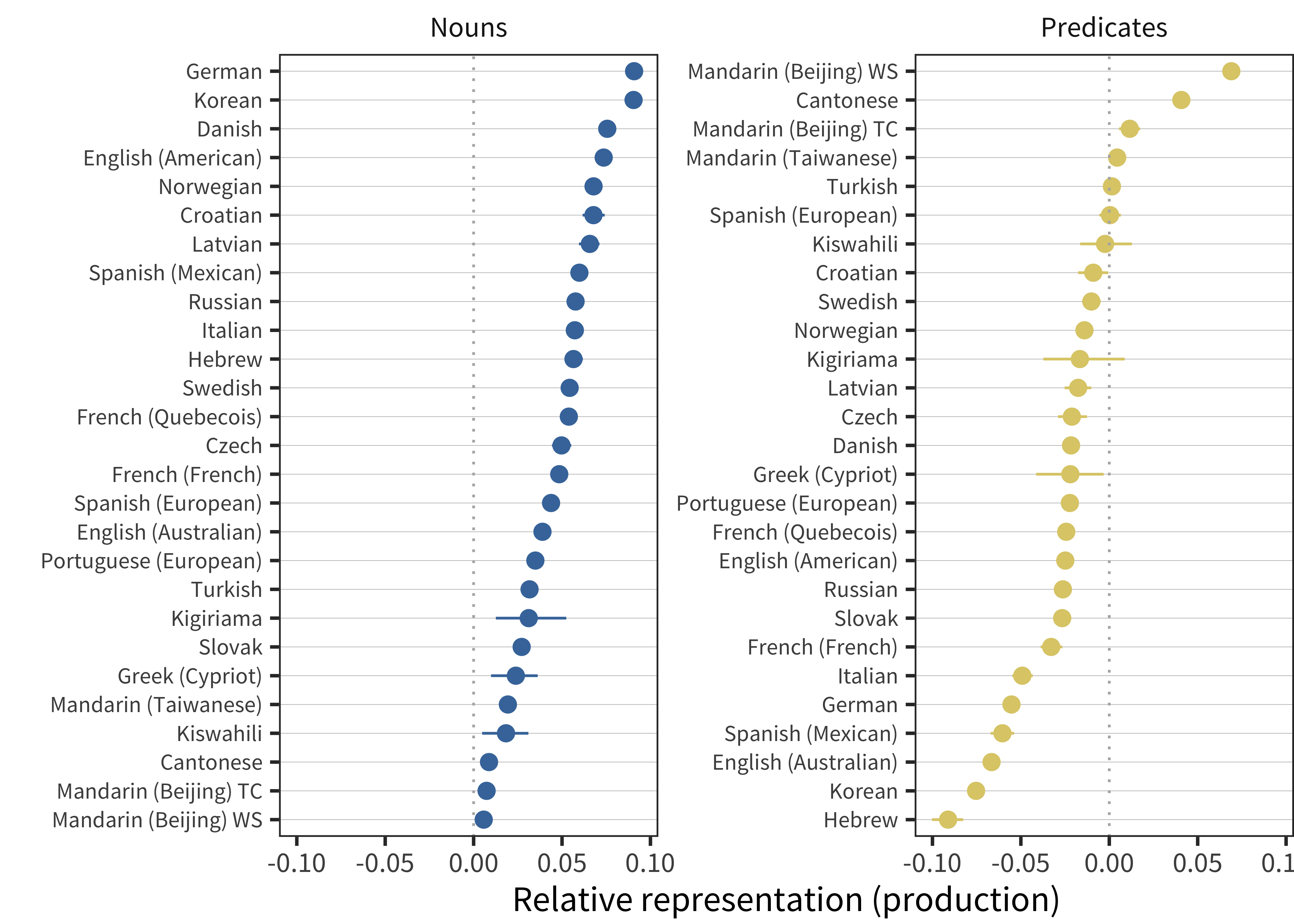
Figure 11.9: Relative representation in vocabulary compared to chance for nouns and predicates for production data in each language (line ranges indicate bootstrapped 95% confidence intervals).
Turning to the language summaries (Figure 11.9), we see a larger pattern of variation in nouns and predicate representation. Every language has a relative over-representation of nouns, though the degree of this over-representation varies. German and Korean have especially large noun biases; the Mandarin and Cantonese datasets have especially low biases (we return to this trend below). Overall the noun bias is both more extreme and more consistent in production data than comprehension. In contrast, predicate representation is both more variable and more negative than we observed for comprehension. Mandarin and Cantonese are the only languages with (in some datasets substantial) over-representation of predicates in early vocabulary. Further, noun and predicate representation is again negatively correlated (r(25) = –0.65.
The negative representation of function words (Figure 11.10) is generally consistent in magnitude with that seen in comprehension. Across all languages, children are reported to produce fewer function words than would be expected by chance sampling.
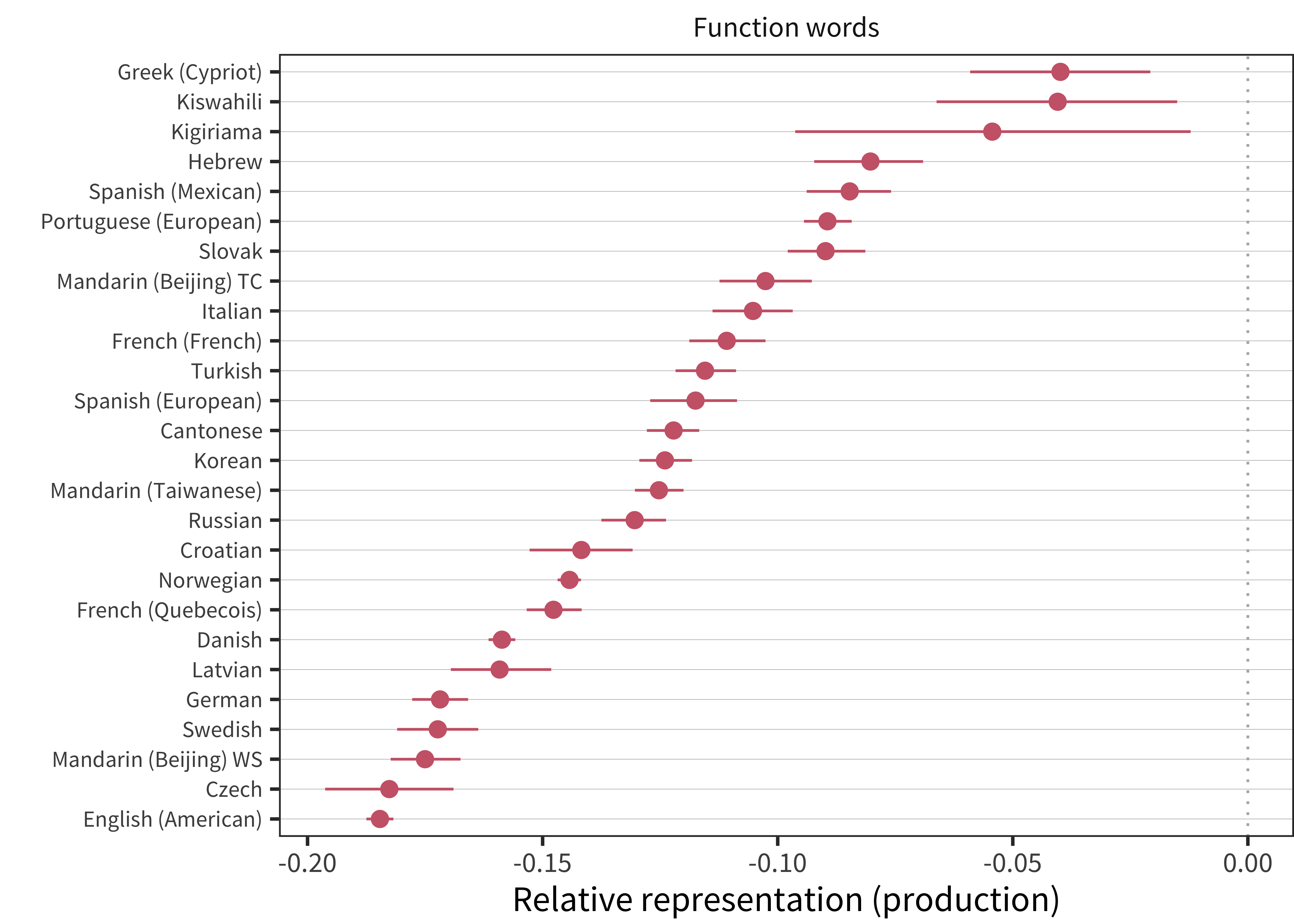
Figure 11.10: Relative representation in vocabulary compared to chance for function words for production data in each language (line ranges indicate bootstrapped 95% confidence intervals).
11.3.3 Predicates
In contrast to Bates et al. (1994), much of the writing about the noun bias has emphasized the contrast between nouns and verbs, rather than predicates more generally. Thus, as an auxiliary analysis to those above, we break down the predicates category further and examine the bias estimates in production for verbs and adjectives, as shown in Figure 11.11. A handful of languages also have adverbs as part of their predicate set; for simplicity and because of the smaller sample size, we omit adverbs from this analysis. We also focus here on production rather than comprehension.
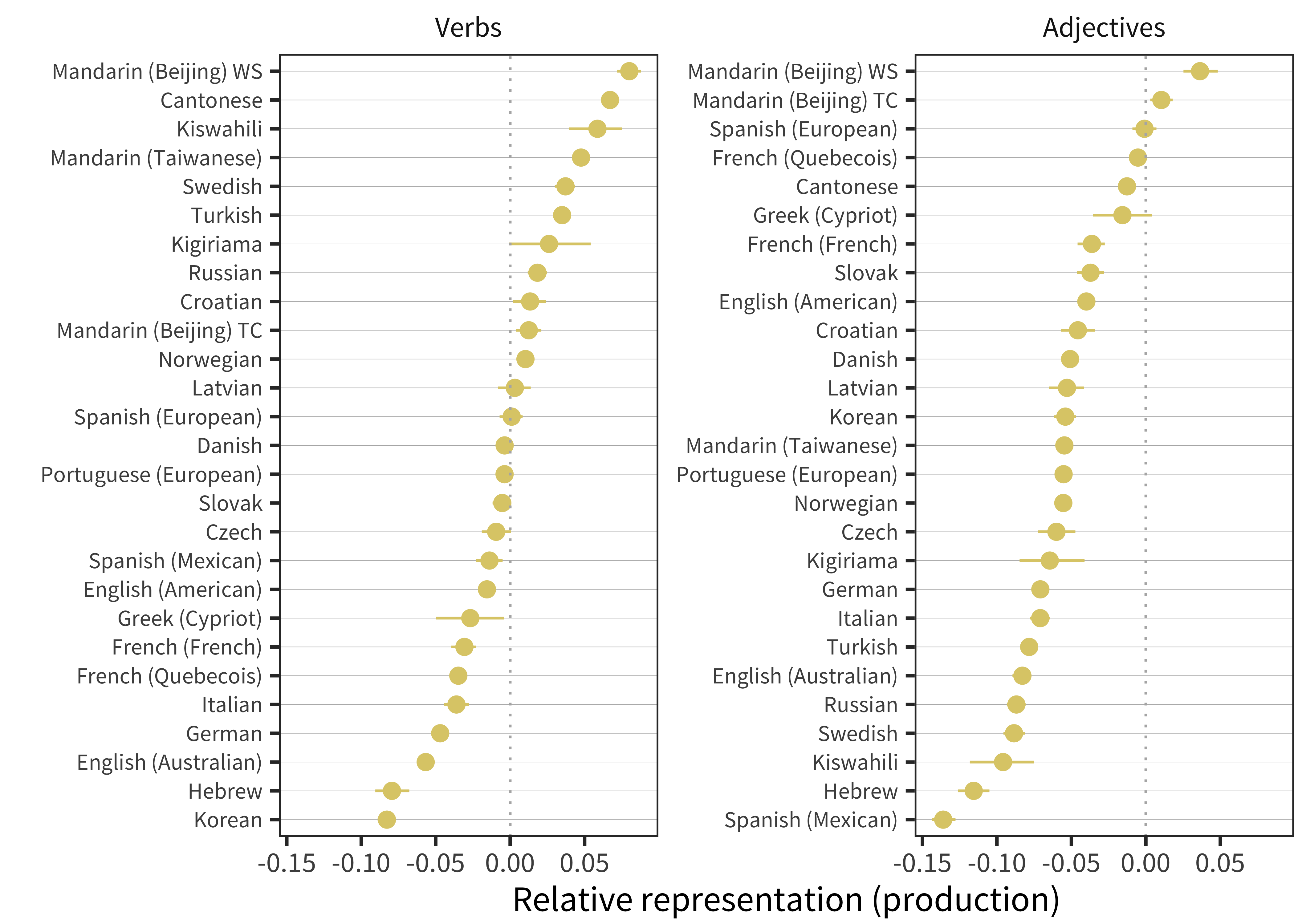
Figure 11.11: Relative representation in vocabulary compared to chance for verbs and adjectives for production data in each language (line ranges indicate bootstrapped 95% confidence intervals).
Overall, this analysis suggests substantial variability in verb bias, with more languages with positive verb biases than languages with a positive predicate bias as a whole. The largest verb biases can be seen in Mandarin datasets, Cantonese, and Kiswahili, but now we see positive biases in Swedish, Turkish, Kigiriama, Russian, Croatian, and Norwegian, a typologically-unrelated set of languages. In contrast, to verbs, adjectives tend to be under-represented in almost all languages, with Beijing Mandarin varieties being the sole exception.
11.3.4 Reliability of bias estimates
Given the seeming differences between comprehension and production noted above, one natural question for further investigation is how consistent estimates of bias are across measures. Figure 11.12 shows – for the sample of languages in which we have data from both WG-type and WS-type instruments – the relative bias we recovered in the analysis above. Somewhat surprisingly, correlations between these different instruments are quite low. Function word bias is negatively correlated between production and comprehension (r(19) = –0.39, p = 0.08). This result is likely due to Kiswahili and Kigiriama, which as discussed above, have the lowest values for function word comprehension. But predicate bias estimates are close to uncorrelated with one another across measures (r(19) = 0.02, p = 0.94), and the correlation between noun bias estimates is modest though positive (r(19) = 0.43, p = 0.05).
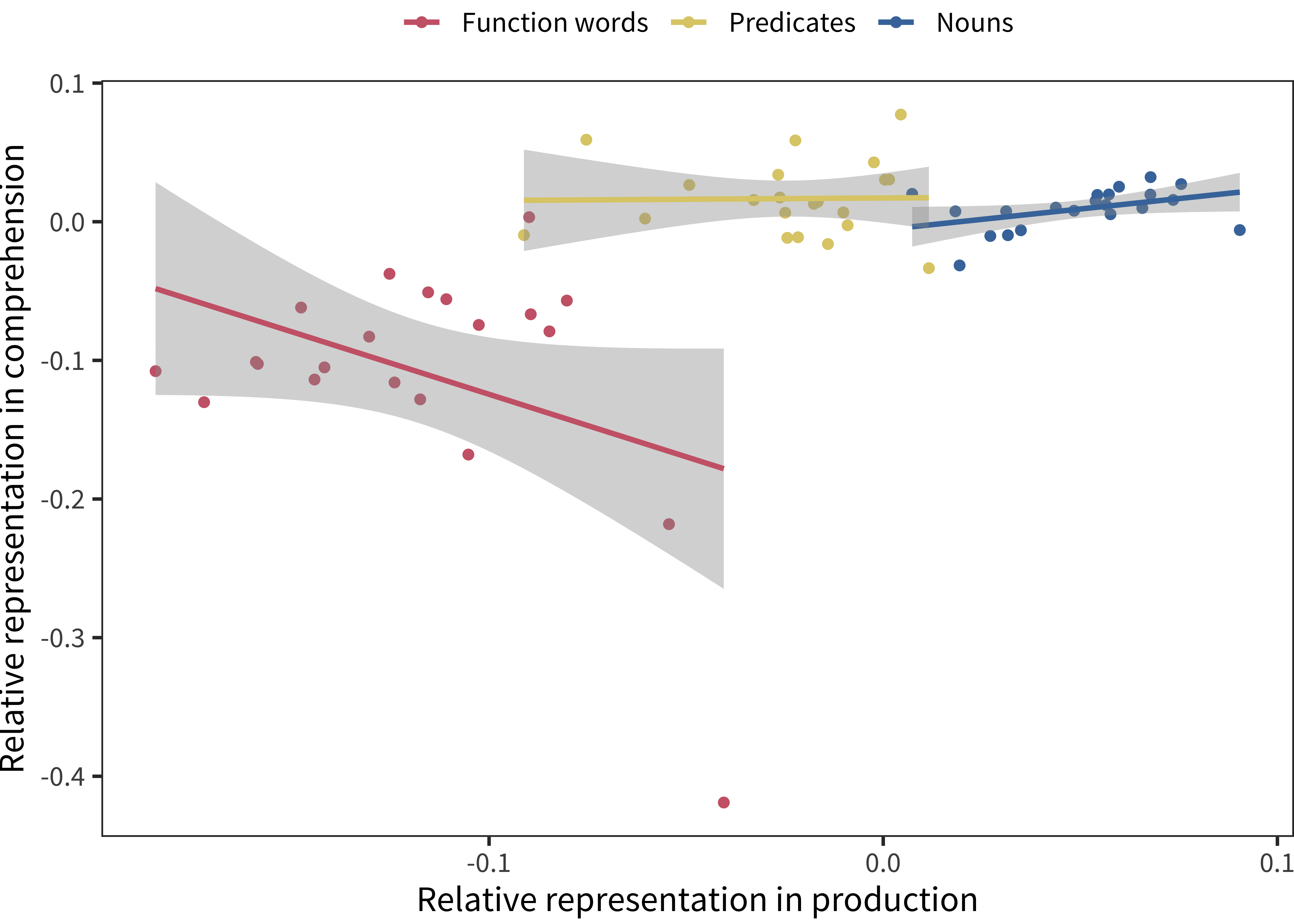
Figure 11.12: Relative representation in vocabulary for each lexical category for comprehension data compared to prooduction data in each language (lines indicates linear regression fits).
This analysis is conducted with only 19 languages and hence has relatively low power (despite the many thousands of children necessary to carry it out). Nevertheless, it raises some important questions. A number of explanations come to mind and appear consistent with the data:
Lexical category bias differs between comprehension and production, perhaps because of different mechanisms at work acquiring words for comprehension vs. production.
Estimates of bias are influenced by the composition of specific forms, so much so that WS- and WG-type forms yield radically different estimates of bias.
Estimates of bias are influenced by the stability of parent report for different measures such that comprehension estimates are less meaningful.
Bias differs developmentally. Perhaps different biases are evident earlier vs. later in acquisition.
We assess each of these explanations in turn.
Our first potential explanation is that category bias is simply different between production and comprehension because vocabulary is different. To test this hypothesis, we need data on a sample of children who are matched in both age and language on which we can compare production to comprehension. Unfortunately, as noted above, data on production from standard WG forms is simply too sparse to perform our bias assessment method; since most children do not produce half of the words on the form, the shape of the bias curves is driven primarily by older children. Thus, in order to assess comprehension/production differences as a source of bias, we examine the Oxford CDI (shown in Figure 11.13). The Oxford CDI is relatively unique in that it includes comprehension questions even later in development, so we can compare bias estimates directly across younger and older children.
In the Oxford CDI data, the measured noun bias for comprehension is 0.05; for production it is 0.07. These values for predicates are –0.03 and –0.08, respectively. These values are somewhat similar to one another, but they do vary beyond the average confidence interval on each (+/- 0.01). Thus, there is some evidence for comprehension/production asymmetries.
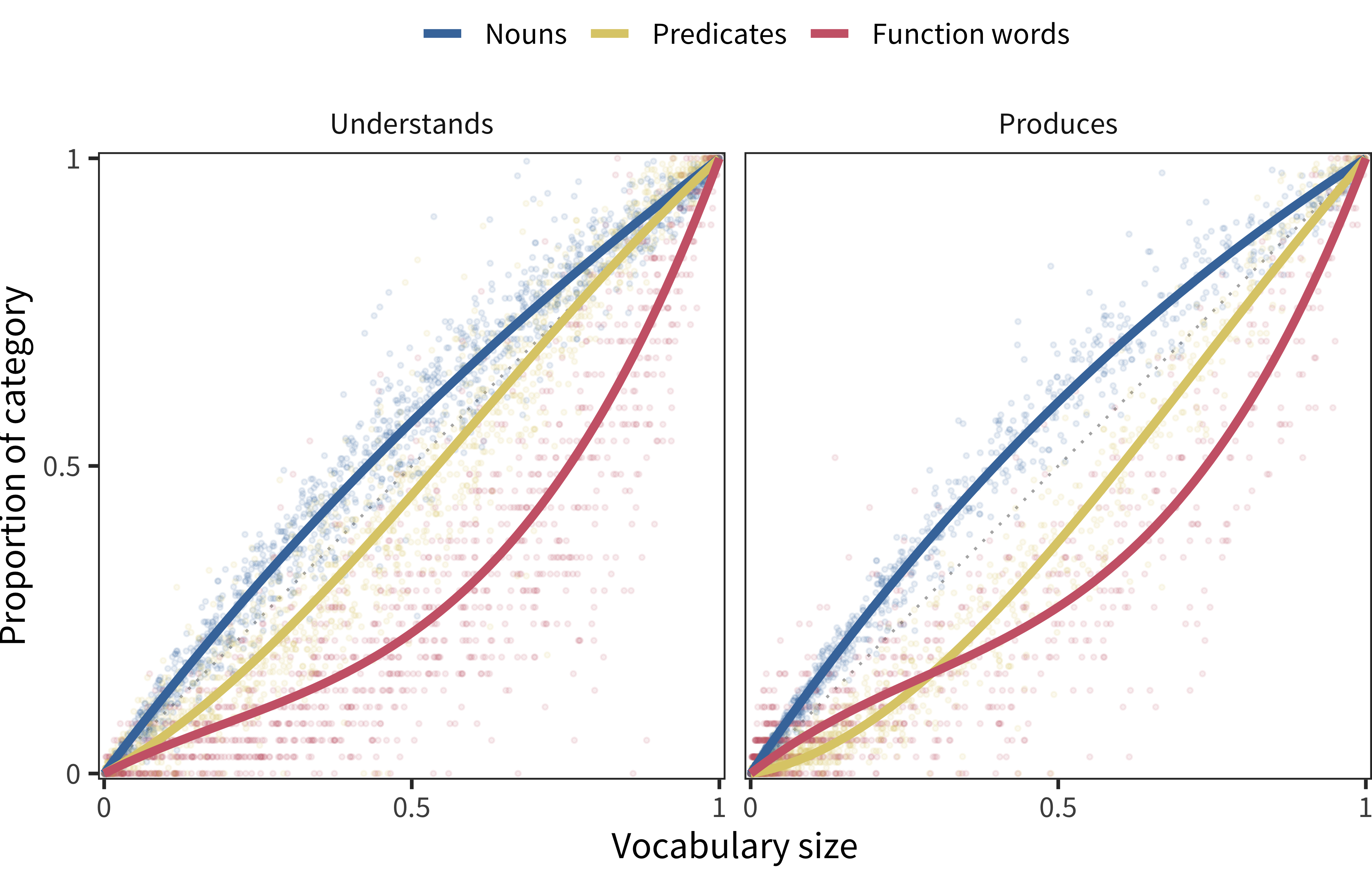
Figure 11.13: For Oxford CDI data, proportion of each lexical category produced by each child as a function of the proportion of all vocabulary items produced by that child. Lines show model fits.
What might be the mechanism for these asymmetries? At least for languages that do not allow argument dropping, producing a predicate typically requires producing other words as well. for example, English-speaking children do not often produce bare predicates. Further, felicitous predicate production requires some ability to combine words syntactically; in contrast, comprehension of predicates (especially verbs) can often be accomplished by guessing based on known arguments (e.g., Gillette et al. 1999). For these reasons, there may be a greater bias against predicates in production compared with comprehension. This explanation is consistent with our data, in which the average production predicate bias is –0.021, while the average for comprehension is 0.013. Thus, comprehension/production asymmetries likely explain some part of the differences we observed above.
The second potential explanation is that bias estimates are related to form composition. Although our method for calculating bias corrects for the number of items from a particular category on a form, it does not correct for the relative difficulty of these items. For example, a form with more predicates might actually show a lower degree of predicate bias – more predicates on the form would imply that some of those predicates are relatively more difficult (because the form designer had “run out” of easy predicates) and hence these predicates would not be checked as frequently by parents. Thus, the lack of correlation between comprehension and production bias measures might be a function of differences in composition across the forms.
We assess this hypothesis in two ways. We examine the relationship between predicate bias and predicate representation on forms (focusing on predicates because they are a minority on the form). Then we consider the case of Mandarin where we have data from two forms with different compositions.
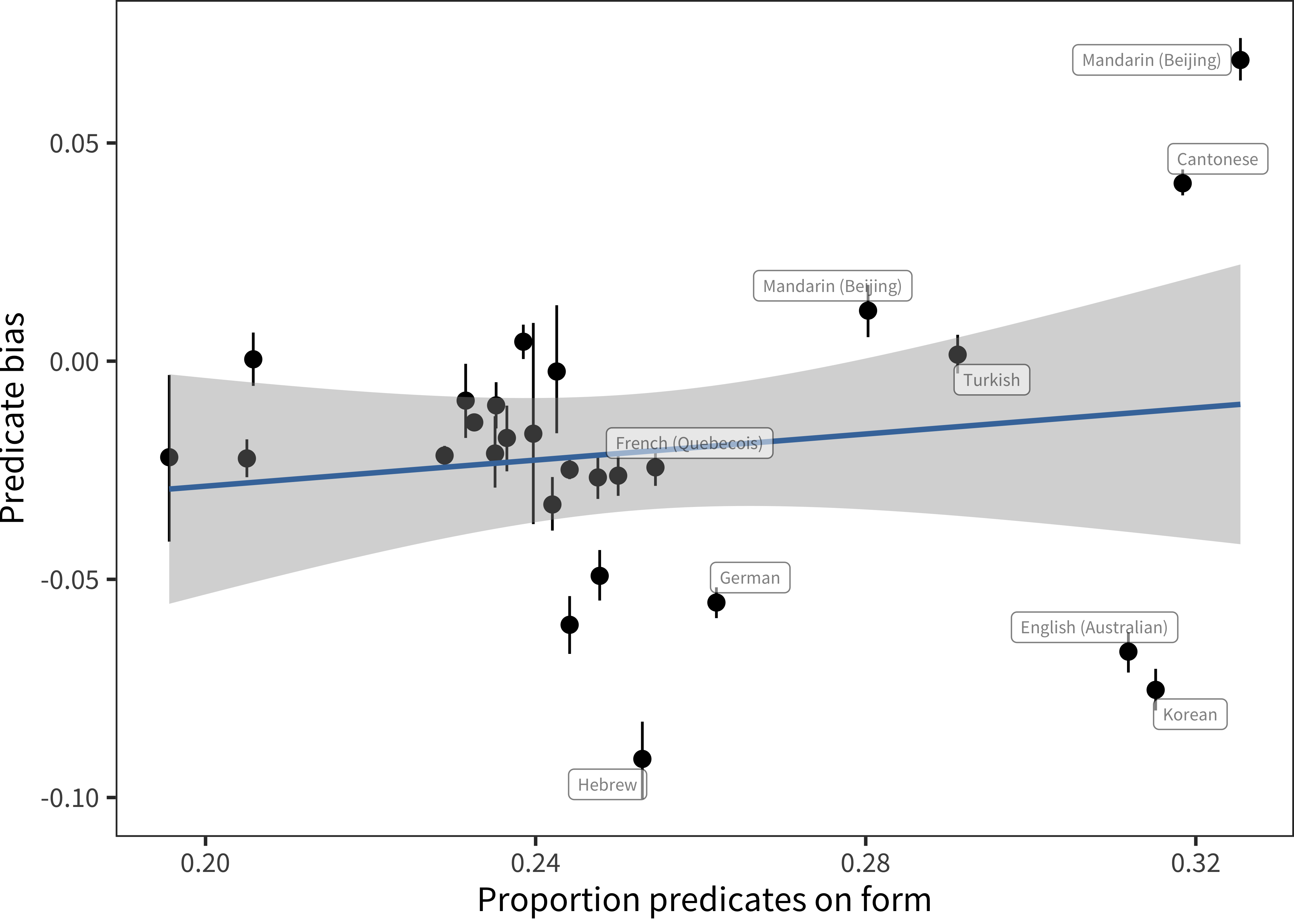
Figure 11.14: Relative representation in vocabulary for predicates as a function of proportion of predicates on form for comprehension data in each language, with languages labelled whose proportion of predicates is greater than 0.25 (line ranges indicate bootstrapped 95% confidence intervals). Blue line show linear model fit.
As shown in Figure 11.14, there is no reliable relation between the proportion of predicates on a form and the predicate bias that is demonstrated (r(25) = 0.15, p = 0.45). Thus, a simple relation between form composition and bias is not supported. On the other hand, it does appear that there is greater variance in this area for those languages with larger numbers of predicates on the form, and those languages with the highest predicate representation do have the highest number of predicates on the form as well. Perhaps the causality is reversed: Greater numbers of predicates have been included in forms for languages like Cantonese, Mandarin, and Korean where the predicate bias is an open theoretical question (or where the acquisition of predicates is of special interest).
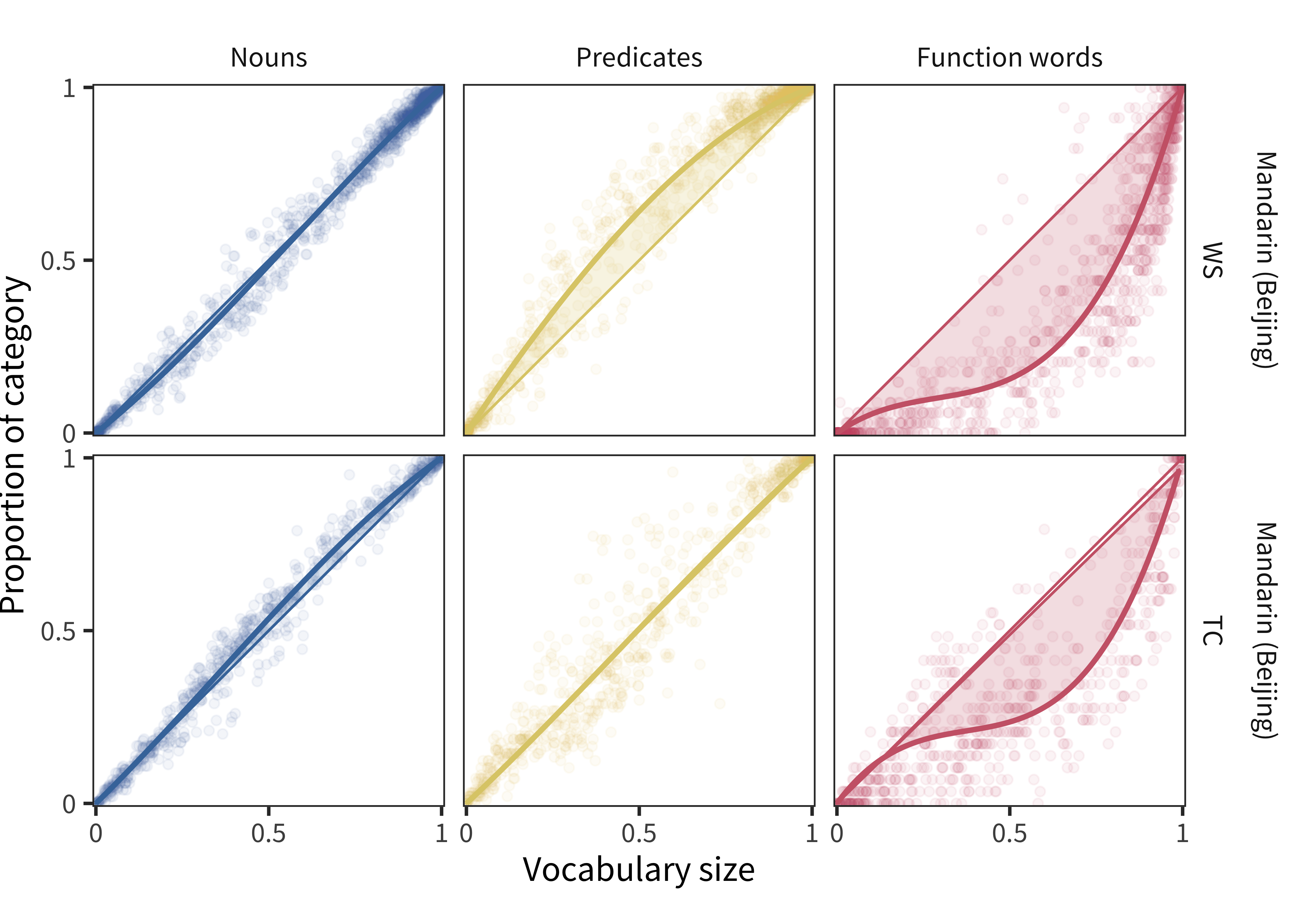
Figure 11.15: For Mandarin WS and Mandarin TC data, proportion of each lexical category produced by each child as a function of the proportion of all vocabulary items produced by that child. Lines show model fits.
The existence of two different forms for Mandarin opens the possibility of a further, more direct test of this issue. The Mandarin WS form (Tardif et al. 2009) and the Mandarin TC (Toddler Checklist; Hao et al. 2008) are completely independent forms but represent large datasets collected on Beijing Mandarin specifically. The Mandarin WS form is 33% predicates and shows overall a 0.069 predicate preference, while the TC form is 28% predicates and shows overall a 0.012 predicate preference. The intersection of these forms yields 330 items, with 30% predicates. Interestingly, the predicate representation for the TC and WS samples, analyzing only shared predicates still differs, if anything more substantially: for WS it is 0.094 and for TC, 0.004.
This result is worrisome – these are samples from the same city and using the same items. They even include very similar age ranges: 16–30 month-olds and 17–30 month olds respectively, with approximately uniform sampling. The suggestion is then that differences in predicate bias can be substantial based on relatively minor details, such as specifics of administration or form context or specifics of sample composition. Extrapolating outward, despite the apparent stability of these estimates under resampling (confidence intervals for bias estimates are around ±0.005 in the analysis above), we should be cautious in over-estimating our degree of certainty in particular bias estimates. Further, these data provide more evidence against the notion that form composition (or at least the specific sample of predicates being assessed) is the primary determinant of bias.
The third hypothesis that we examine is the possibility that comprehension and production bias estimates differ because of differences in parent report processes. This explanation is related to our first but distinct – here, we appeal to the relatively lower psychometric stability of comprehension reports. On the other hand, we presented evidence in Chapter 4 that comprehension, while apparently less reliable, is still fairly reliable and does not differ too much by syntactic category. Further, in other chapters (e.g. Chapter 10) we saw strong consistency between comprehension and production results. Thus we do not believe that pure measure unreliability is a good explanation of bias.
The final hypothesis that we examine is that there are developmental differences in bias. Such differences would help to explain the observed differences between bias in early comprehension and later production. To address this question, we split data from each language and form into older and younger groups at the median of the data for that sample. We then recomputed our bias estimates, shown in Figure 11.16. There was a developmental difference such that older children showed less of a negative function word bias, but differences in noun and predicate bias were very slight for most languages. Thus, overall we do not see evidence that bias estimates for nouns and verbs are globally different for older vs. younger children.
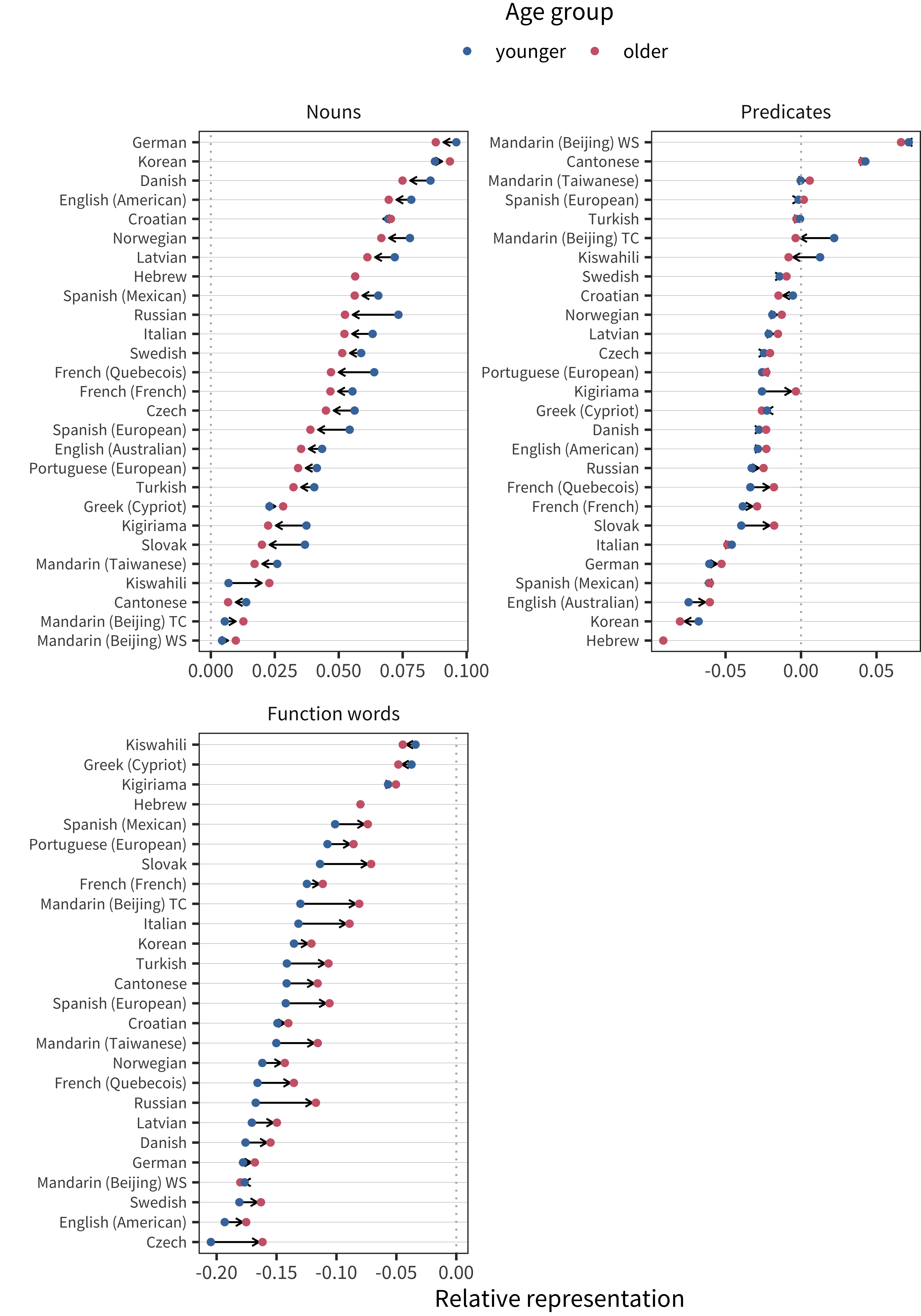
Figure 11.16: Relative representation in vocabulary for each lexical category per age group for production data in each language.
In sum, we did not find strong support for effects of form composition, measure reliability, or age on bias estimates. Each of these factors, of course, could contribute in part to the mismatch between WG comprehension and WS production estimates, but none was strongly supported. On the other hand, data from the Oxford CDI suggested some differences in bias estimates between comprehension and production on the same form, with the bias against predicates and for nouns being substantially more pronounced for production than for comprehension. Further, data from two different Beijing Mandarin datasets suggest possible factors relating to population and administration.
11.4 Discussion
This chapter presented a comprehensive examination of the issue of biases for and against particular syntactic categories in acquisition. Building on earlier work by Bates et al. (1994), we created a quantitative measure of noun, predicate, and function word bias, and examined variability in these measures across languages. Overall, a number of generalizations emerge regarding the composition of early vocabulary development.
Nearly every language showed a positive bias for nouns in children’s early vocabularies, though the degree of this bias varied and was more pronounced in production. And further, every language showed a substantial bias against the early acquisition of function words, supporting the generalization that these are acquired much later than content words, despite their typically higher frequency in the ambient language (see Chapter 10). This bias was larger, on average, than noun and predicate biases.
In children’s early comprehension vocabularies, there was variability in the degree of predicate representation; in early production vocabularies, as has previously been reported, languages were mostly biased against predicates. There were a few notable exceptions, however, including Mandarin and Cantonese. This conclusion largely supports previous work on these languages (e.g., Tardif 1996; Tardif, Shatz, and Naigles 1997). Our Mandarin findings contrast with our finding of no positive predicate bias in Korean, which differs from the predicate bias found by Choi and Gopnik (1995) in a smaller study. Interestingly, predicate biases in production were in part driven by a relatively consistent bias against adjectives with more variability in the bias for verbs.
Finally, measures of bias in production and comprehension were not highly correlated with one another, especially for predicates and function words. There are likely many causes of this pattern, but one possible explanation appears to be greater predicate comprehension compared to production. On the other hand, within two different Mandarin production samples (even subset to the same items), we saw some differences. Thus, one important caveat to the work presented here is that – despite the huge amount of data going into our bias estimates – the resulting measurements may not be as stable or accurate for a particular language as we had hoped. Leaving aside this caveat, a suggestive conclusion of our investigation is that constraints on the production of predicates – that is, that verbs, adjectives, and adverbs are rarely uttered alone – might lead to their relative under-representation in production reports. Put simply, if you need to say nouns along with other words but you can also say nouns alone, on average the other words will look less frequent and less well-represented in the vocabulary.
In sum, we see clear evidence for a positive noun bias and a negative function word bias, with more cross-linguistic variability present for predicates. The precise measurement of predicate bias and an explanation of its variability are important topics for future work.
This effect may also reflect aspects of CDI form design, e.g. “running out of nouns” to learn: children may increasingly be learning nouns that are not on the forms.↩︎
We experimented with a number of model classes and found that these polynomial models seemed flexible enough to provide good fit to a wide variety of patterns of data. Because our concern is not making statistical inferences about the shape of these curves (but rather estimating the area under them) we are not specifically worried about overfitting.↩︎