Chapter 12 Vocabulary Composition: Semantic Categories
Following the approach in the previous chapter, we next investigate the consistency of semantic content categories across languages. By analogy with the “noun bias,” we ask for a range of semantic categories whether early vocabulary development in some languages is biased for or against items from these categories. For example, are some languages more “vehicle biased” or “animal biased” than others? Consistent biases across languages can provide hints regarding attentional or conceptual factors influencing early word learning. We begin by exploring general patterns in semantic category bias and then focus specifically on a few theoretically-interesting conceptual domains, like words for time, color, body parts, and logical operators.
12.1 Introduction and methods
In contrast to the “noun bias” literature, where a wide variety of hypotheses have been articulated over the preceding decades, analyses of differences in early vocabulary content have been less frequent. Thus, our current analyses are more exploratory than those presented in the previous chapter. One notable piece of prior work is an analysis of cognitive biases in the early language of international adoptees by Snedeker, Geren, and Shafto (2012) and we discuss those results further here and in Chapter 17, but those data are limited to English learners; our goal is to measure cross-linguistic/cross-cultural variability.
Given the exploratory nature of this chapter’s analyses, we focus on WS-type forms and production measures. As discussed in previous chapters, we have reason to believe these will be most reliable; further, we can take advantage of the longer length and larger set of categories available on most WS-type forms.
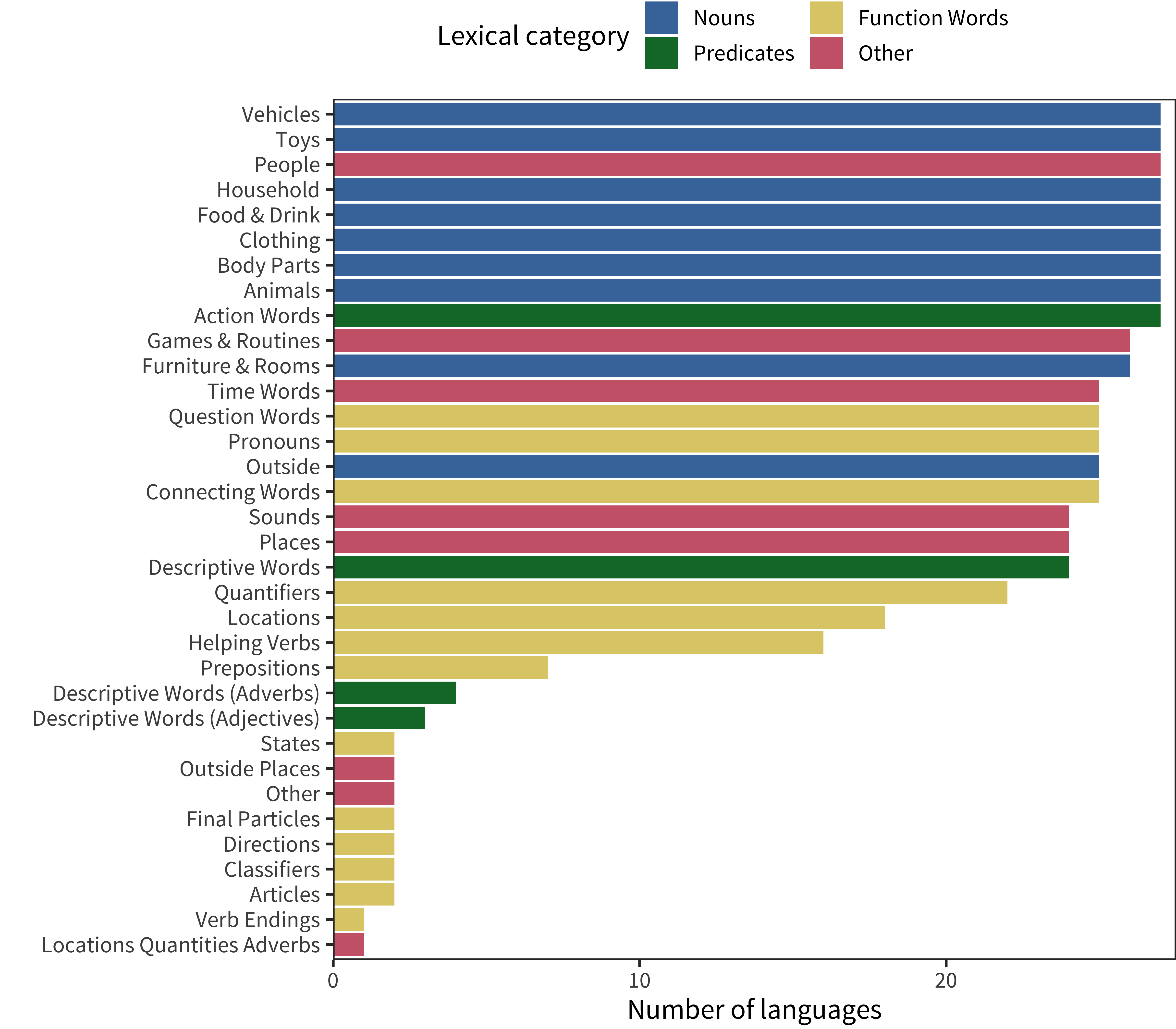
Figure 12.1: Number of languages whose forms contain each semantic category.
Rather than taking on the daunting task of creating novel semantic categorizations across languages, we make use of the fact that CDI forms are typically structured into semantic categories (e.g., Animals or Body Parts). As Figure 12.1 shows, while some of these semantic categories are shared across many instruments, there are others that are quite rare (often corresponding to specific syntactic or semantic categories that are of interest in particular languages). We focus on those semantic categories with greater representation in the data. Further, to avoid duplicating our analysis in Chapter 11, we focus on those semantic categories that fall into “nouns” and “other” lexical classes. Typically most or all of the predicates and function words we analyzed in that prior chapter are grouped into a small number of categories, thus adding categories like Action Words or Descriptive Words would simply repeat the prior analysis. This filtering step leaves 14 categories: Animals, Body Parts, Clothing, Food & Drink, Furniture & Rooms, Games & Routines, Household, Outside, People, Places, Sounds, Time Words, Toys, Vehicles.
We first illustrate our approach using data from the English WS form alone. Analogous to the plots in Chapter 11, Figure 12.2 shows areas where the data deviate from the pattern of category acquisition predicted by random item sampling. The size of the shaded region above vs. below the diagonal gives evidence of over- vs. under-sampling for a particular semantic category (panels are ordered by the size of the bias). We omit the full distribution of datapoints as the visual impression is clearer when only shaded regions are shown.
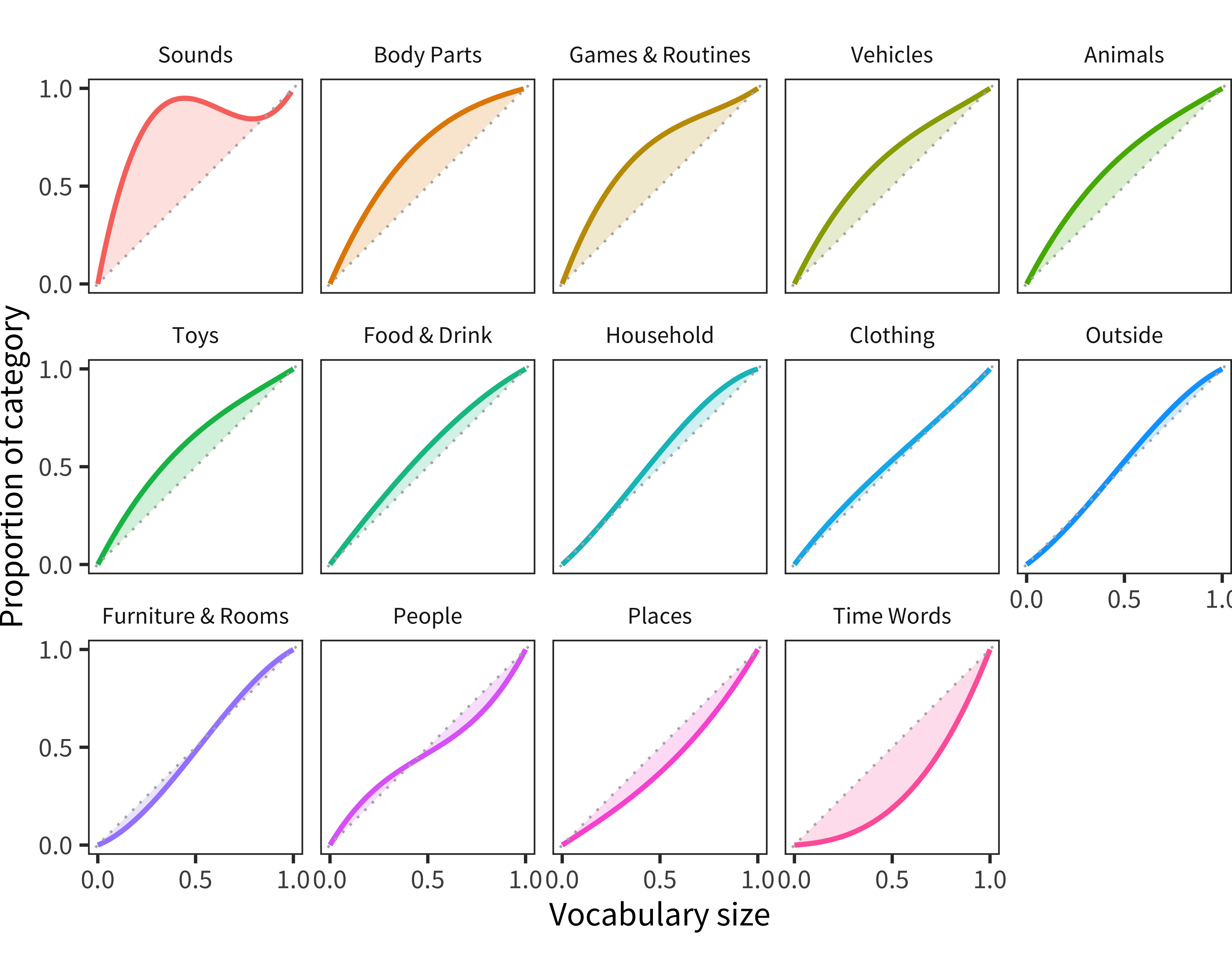
Figure 12.2: For American English WS data, model fit curves for proportion of each semantic category produced by each child as a function of the proportion of all vocabulary items produced by that child.
Many of the results of this analysis for English are expected. Sounds items (onomatopoeia) are heavily over-represented, as are Body Parts, Games & Routines, and to a slightly lesser extent, Toys, Animals, and Vehicles. These particular biases are likely related to particular parenting practices, cultural emphases (for example, on animal names), and young children’s’ idiosyncratic interests (DeLoache, Simcock, and Macari 2007). The largest under-representation across categories is Time Words. This pattern is consistent with a body of work on children’s acquisition of the semantics of time words that suggests that children struggle with understanding these complex terms through age five (Harner 1975; Clark 1971; Tillman and Barner 2015; Tillman et al. 2017). We next turn to how this pattern varies across languages.
12.2 General Results
12.2.1 Individual domains
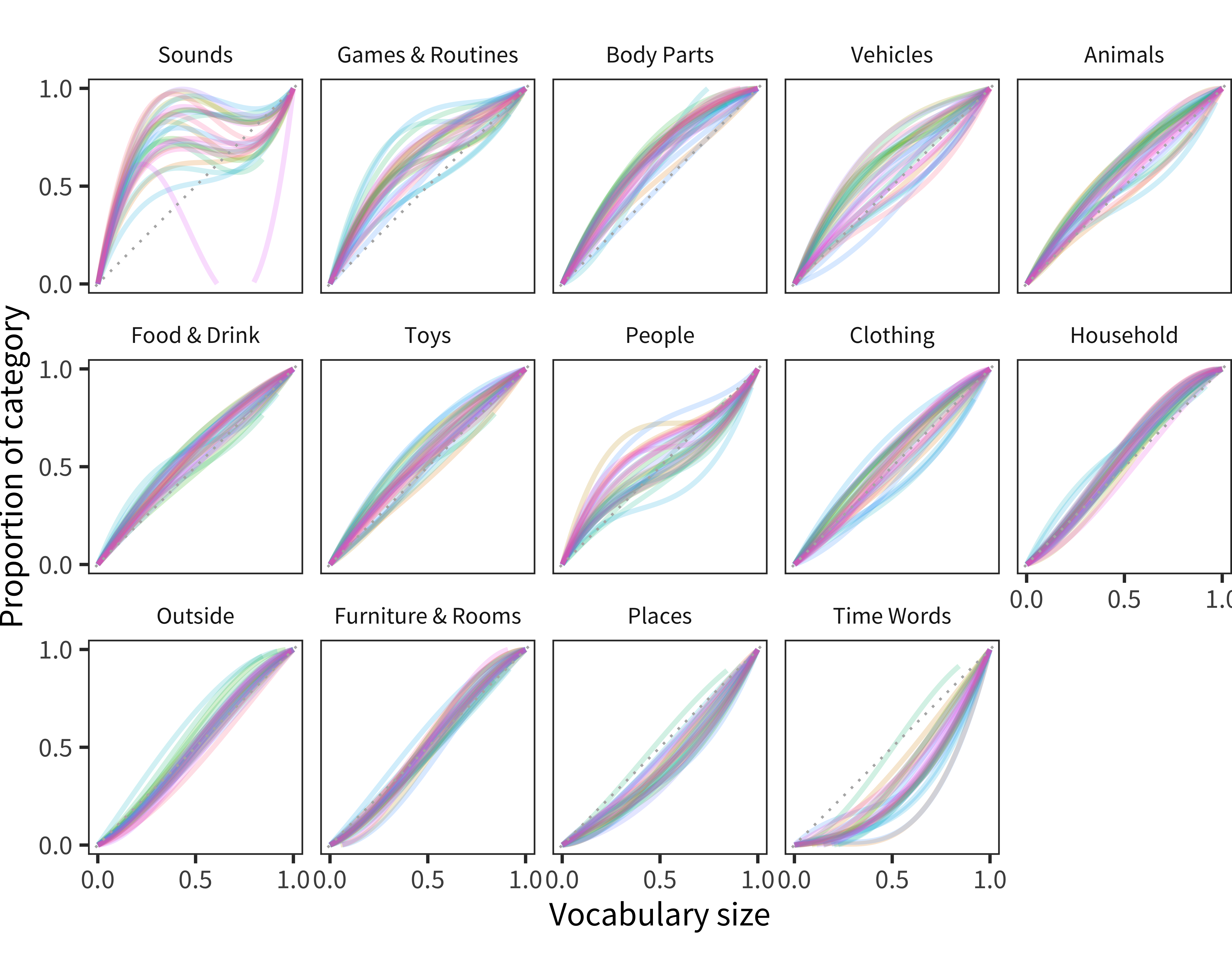
Figure 12.3: Model fit curves for each semantic category as a function of vocabulary size for each language.
Because there are so many different languages represented in this analysis, the simplest analysis examines the spread of languages across categories (Figure 12.3). Somewhat surprisingly, the ordering of categories looks quite similar to what was observed in English. Sounds, Games & Routines, and Body parts are all over-represented. Vehicles, Food & Drink, Animals, and Clothing all are more variable across cultures, as is People. Small Household Items, Outside Things, and Furniture & Rooms show variability but overall less bias. Finally, Places and Time Words are both under-represented systematically across all languages.
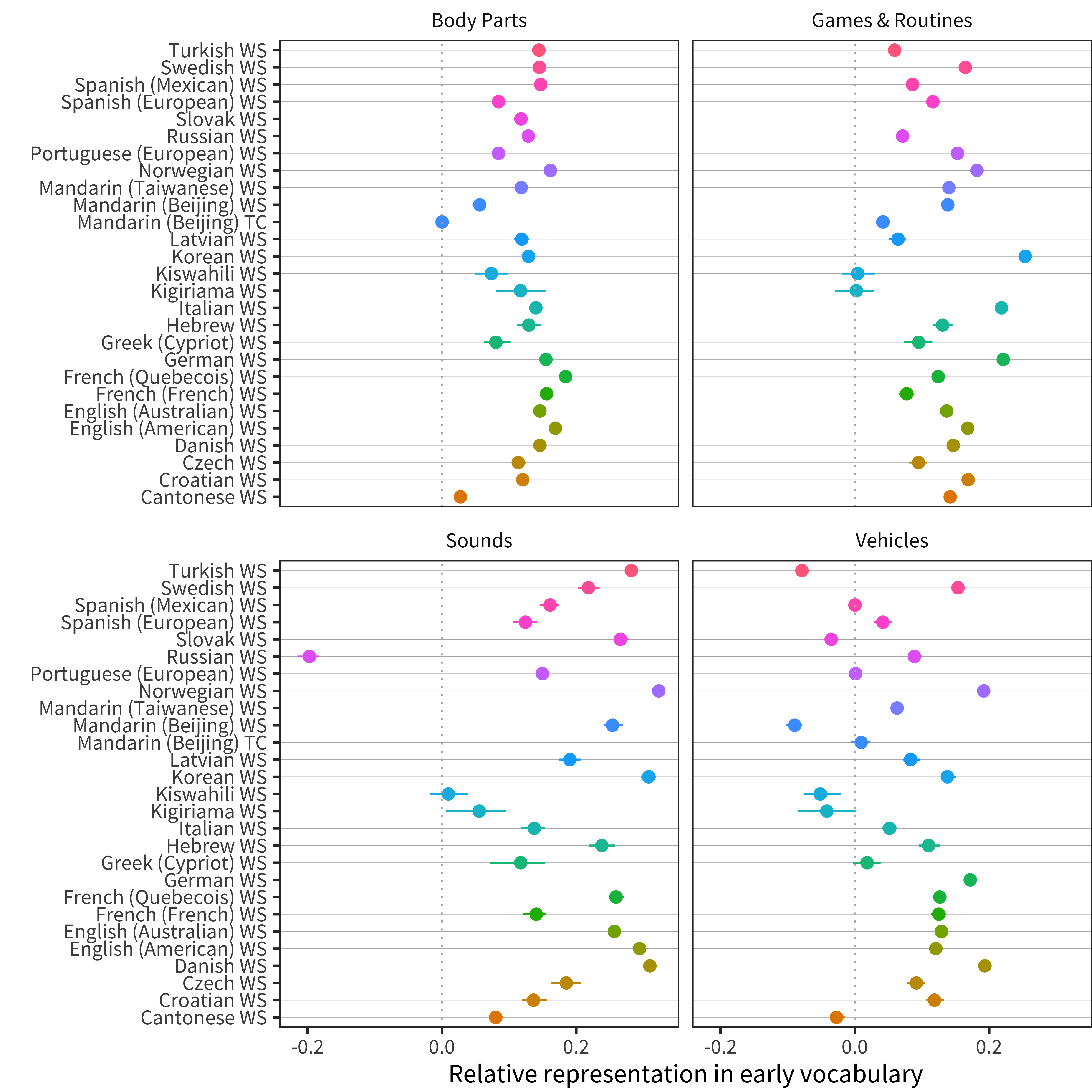
Figure 12.4: Relative representation in vocabulary compared to chance for categories that tend to be over-represented across languages (line ranges indicate bootstrapped 95 percent confidence intervals).
We next zoom in on the most highly over-represented categories (Figure 12.4). The highest mean comes from Body Parts, which are over-represented in just about every language (Andersen 1978). Interestingly, the three datasets with the lowest proportion of Body Parts are the two Mandarin datasets (WS and TC) and the Cantonese WS data. Games & Routines are generally over-represented but somewhat more variable, with Kiswahili, Kigiriama, and Mandarin TC data lowest. Sounds are quite highly variable but almost all positive, with Russian being the outlier. Inspection of these items shows negative developmental trajectories for a number of words in the Sounds category. We believe these data are likely an artifact of parents feeling that they should “trade off” with noun labels in the Animals category, and hence that items in the Sounds category are “baby words” and should be discounted. Finally, words in the Vehicles category appear more variable but have positive bias across most language families.
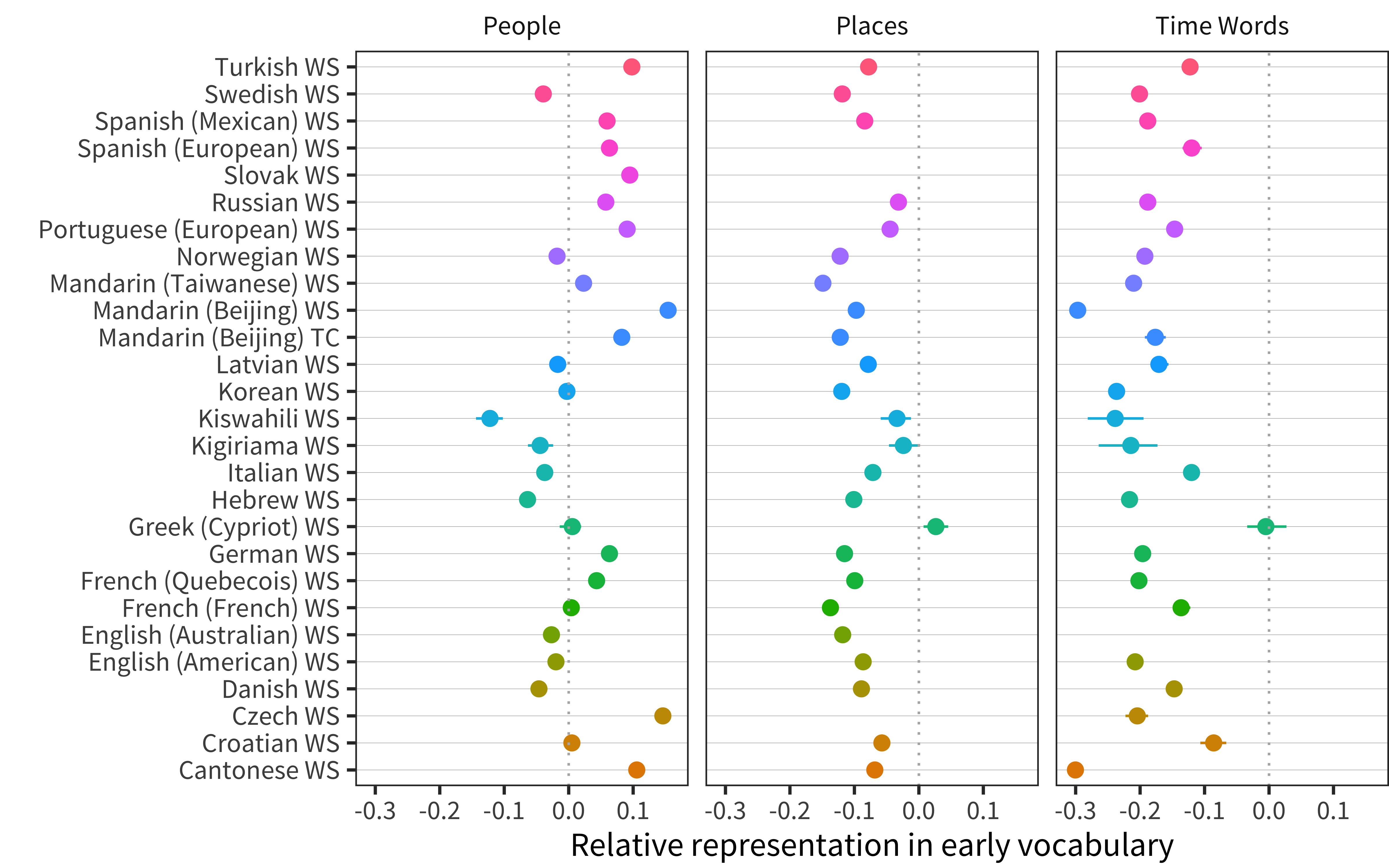
Figure 12.5: Relative representation in vocabulary compared to chance for categories that tend to be under-represented or highly variable across languages (line ranges indicate bootstrapped 95 percent confidence intervals).
We next consider People, Places, and Time Words (Figure 12.5). People has highly variable bias, with some languages under-representing and others over-representing. Tardif et al. (2008) speculated that names for people were a substantial part of children’s earliest words, but that may reflect that study’s use of Mandarin and Cantonese data where people terms are very over-represented due to cultural emphasis on family connections. Surprisingly, despite the relatively multi-generational and family-centric nature of children’s experience in Kenya (Alcock and Alibhai 2013), people words were relatively under-represented in Kiswahili and Kigiriama.
In contrast to the heterogeneity in bias for People words, words in Places and, especially, Time Words were almost uniformly under-represented in children’s vocabulary. As noted above, time is known to be conceptually difficult for children. Time words offer a number of conceptual challenges in terms of mapping an ordered set of durations (second < minute < hour < day, etc.) to a set of concepts that do not map cleanly onto perceptual experience. Less has been written about children’s understanding of geographical vocabulary, however. Many of the same conceptual difficulties that are true of time also may hold true for larger locational/geographical hierarchies (neighborhood < city < state < country). Or alternatively, the under-representation of places in children’s early vocabulary may simply reflect the relative lack of diversity of their experiences with some of the items that traditionally populate this section (e.g., beach, camping, church, circus to name the first four). See Chapter 4 for some evidence that camping especially may be a poor reflection of children’s overall language experience.
12.2.2 Dimensionality reduction
Our next analysis takes an exploratory dimensionality-reduction approach. Rather than examining each semantic category individually, we consider the space defined by variation in semantic preferences by running principal components analysis (PCA) on these data. PCA is a dimensionality reduction technique that projects high-dimensional data (e.g., bias by semantic category for each language) into a set of orthogonal dimensions where lower dimensions capture as much of the variance as possible.
Standard PCA requires datasets without missing data, so we removed languages with missing categories. This analysis thus includes 23 language/form combinations and 13 categories. (We exclude words from Sounds because of the issue with Russian in this category and other missing data). The total variance explained by the first principal component es 44% and by the second es 16%.
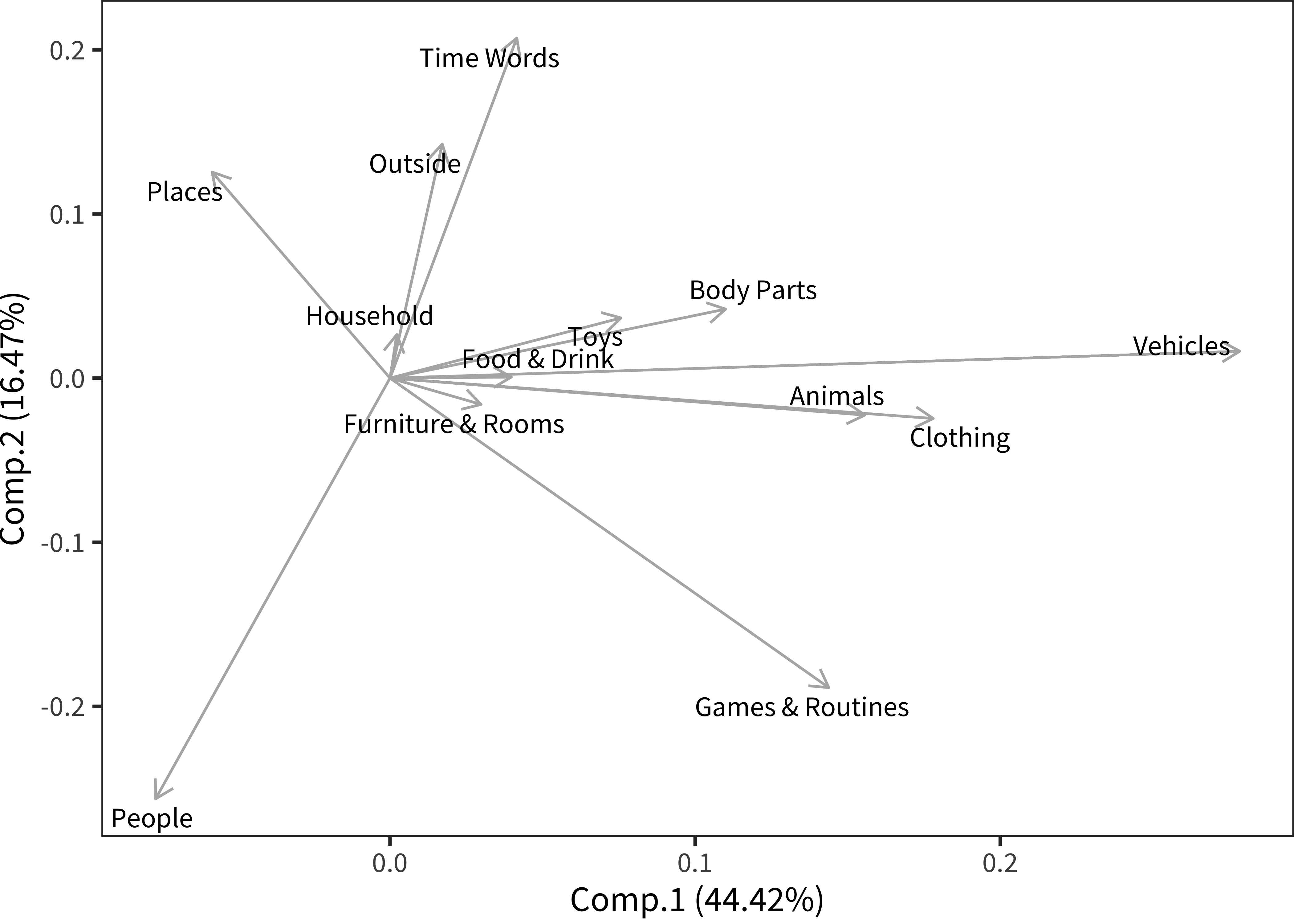
Figure 12.6: Loadings of each semantic category.
Figure 12.6 and Figure 12.7 show the loadings of semantic categories on these two components and the data projected into the space of the first two principal components, respectively. We examine the loadings of categories on components first. We see that the first component (PC1) appears primarily to capture increases in vehicles, animals, and clothing relative to places and people. Intuitively, this dimension seems like it might be distinguishing the tendency of children learning a language to name small objects vs. other entities. In contrast PC2 appears to capture variance related to differences between people and games/routines (both of which are categories over-represented in the earliest words) compared with places, outside words, and time words (most of which are quite conceptually difficult).
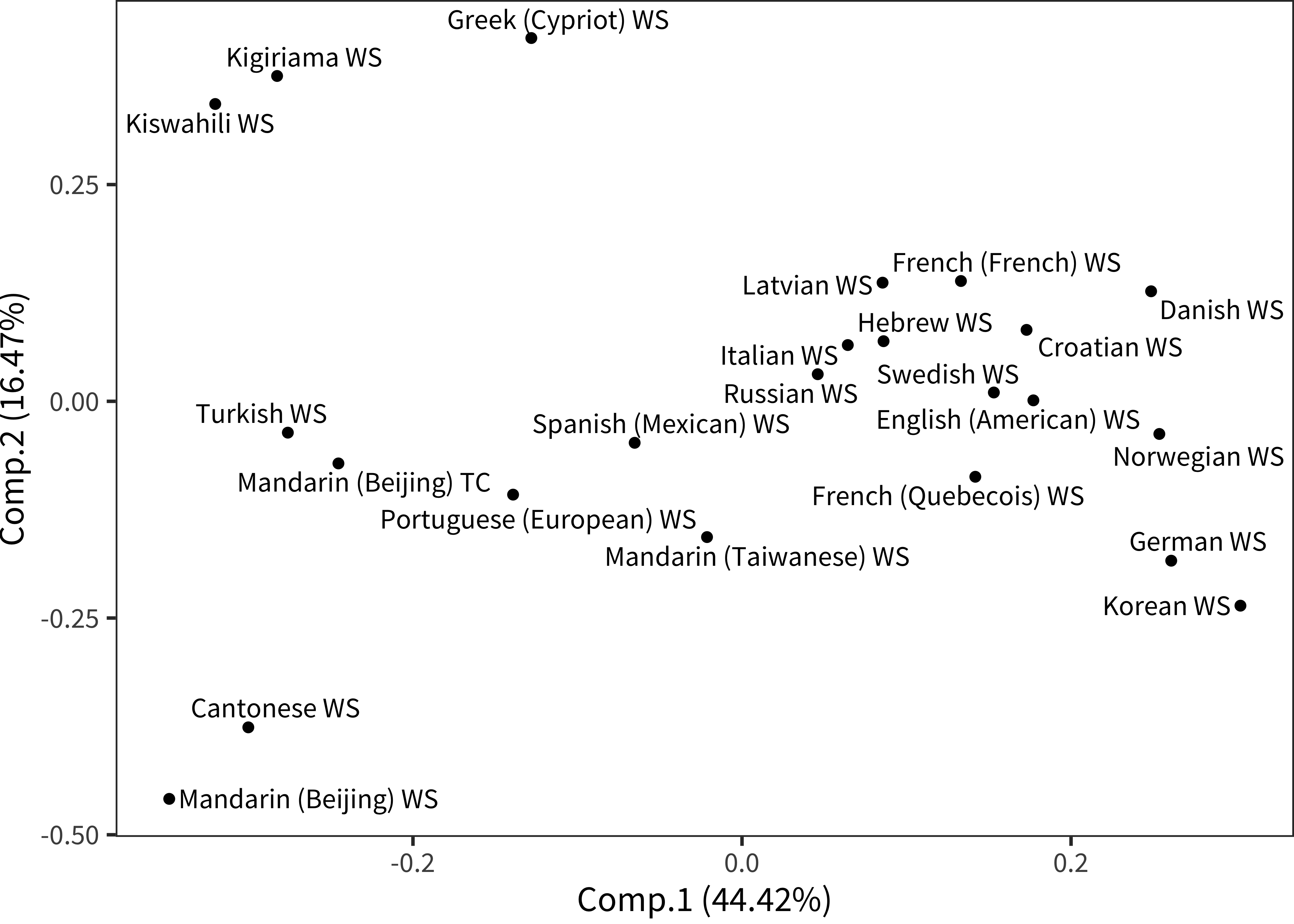
Figure 12.7: First two principal components for each language.
These dimensions can be clarified by examining the projection of languages into the reduced-dimensionality space. PC1 appears to be distinguishing languages in which children name objects and animals. English, many Northern European datasets, and Korean are clustered at the far right, with high scores on Vehicles, Clothing, and Animals. In contrast, for those datasets that do not show over-representation in these categories, we see PC2 being more diagnostic: Mandarin and Cantonese WS data are very far towards the direction of people and games/routines. In contrast, Kiswahili, Kigiriama, and Cypriot Greek are especially far in the direction of Outside and Places words, perhaps consistent with the datasets being collected in rural and semi-rural areas.
Overall, this analysis reveals some interesting structure, that could be tested in future studies. On the other hand, we caution that care should be taken not to over-interpret. In particular, as we saw in Chapter 11, within-culture differences (e.g., Mandarin TC vs. Mandarin WS) are as large in size as between-culture differences. Thus, understanding factors underlying category bias variability should be an important goal for future work.
12.3 Individual conceptual domains
In this section, we isolate individual items from specific domains of interest. Our approach is to use the “universal lemma” mappings (see Chapter 3) to find matching lexical items across languages. The specific domains we consider are time, color, body parts, and logical words. We also investigated spatial prepositions and number words, but do not include them here. Spatial prepositions present a wide variety of mapping issues since lexical items “cut up” space differently across languages (see e.g., Bowerman 1996). And number words are not found on enough CDI forms to have sufficient data for inclusion. Thus, although these categories are of major theoretical interest, other approaches beyond the relatively crude mapping approach we followed here will be necessary.
12.3.1 Time
As discussed above, the semantics of time words are very challenging for children through middle childhood (Tillman and Barner 2015; Tillman et al. 2017). Despite this, parents report that children do produce some of them by age 2.5. The set of words with sufficient translation equivalents for inclusion was after, day, later, morning, night, now, today, tomorrow, yesterday.
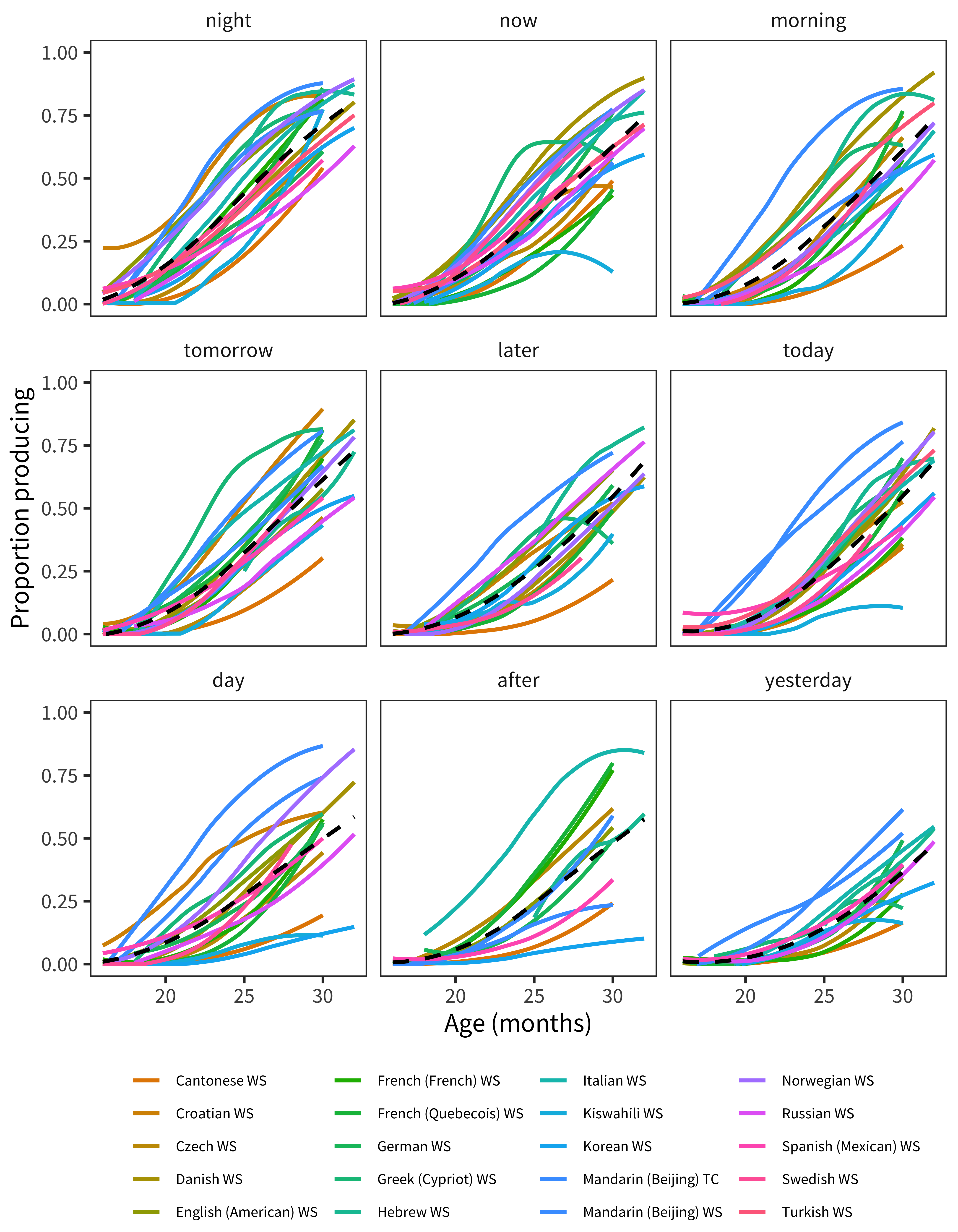
Figure 12.8: Developmental trajectory of each time word in each language.
Figure 12.8 shows trajectories for time lexical items across languages, sorted by difficulty. Because night is typically signaled by darkness, it is perceptually very concrete and likely easier than other time words. Similarly, now seems relatively more straightforward given that it has a common imperative meaning in sentences like “give me that right now.” In contrast, the latest-acquired is yesterday, which is highly abstract and requires a sort of “mental time travel” in thinking retrospectively beyond the “here and now” (Busby and Suddendorf 2005). While tomorrow shares those same features, it appears to be learned earlier than yesterday on average, whether due to frequency or other factors.
12.3.2 Color
Color word acquisition has been a focus of interest at least since early work by Carey (1978)’s influential study of “fast mapping.” Although early work suggested that color words were learned almost simultaneously (Bartlett 1977), more recent studies have described a more protracted trajectory of partial knowledge. Many children learn some color words and overextend these to cover the rest of color space (Wagner, Dobkins, and Barner 2013). Adding to the complexity of this issue are the substantial cohort changes in the age at which colors are learned: while school-aged children struggled with their colors 50-100 years ago, more recently children learn colors in the age range spanned by the CDI forms (Bornstein 1985).
There is tremendous cross-linguistic variation in the overall level of color vocabulary (Kay et al. 2009). We take advantage of the fact that most of the languages in our dataset have relatively large color vocabularies, which we can assume means that individual colors probably have relatively similar extensions.22 Despite this, most CDI forms do not include all the basic level color words. The set of color words with sufficient translation equivalents for inclusion was black, blue, green, red, white, yellow.
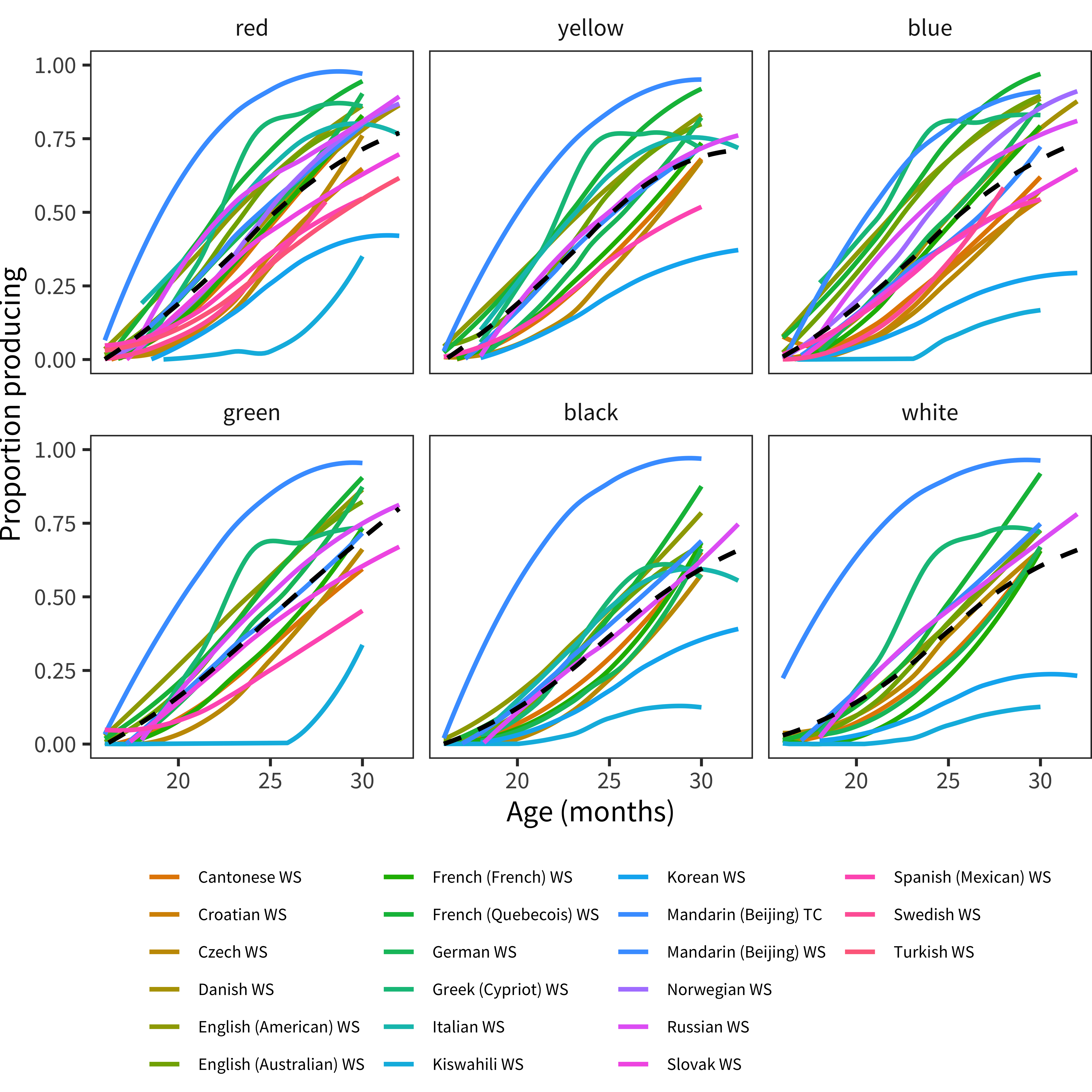
Figure 12.9: Developmental trajectory of each color word in each language.
In contrast to the variability in overall level, the sequence of learning is fairly consistent across languages. In this set of words (Figure 12.9), we see that red is typically the first learned, although there is substantial variability in when it is learned. It is followed by yellow, blue, and green, with black and white following behind, consistent with reports by Wagner, Dobkins, and Barner (2013). (See Yurovsky et al. (2015) for an account of factors involved in color word learning).
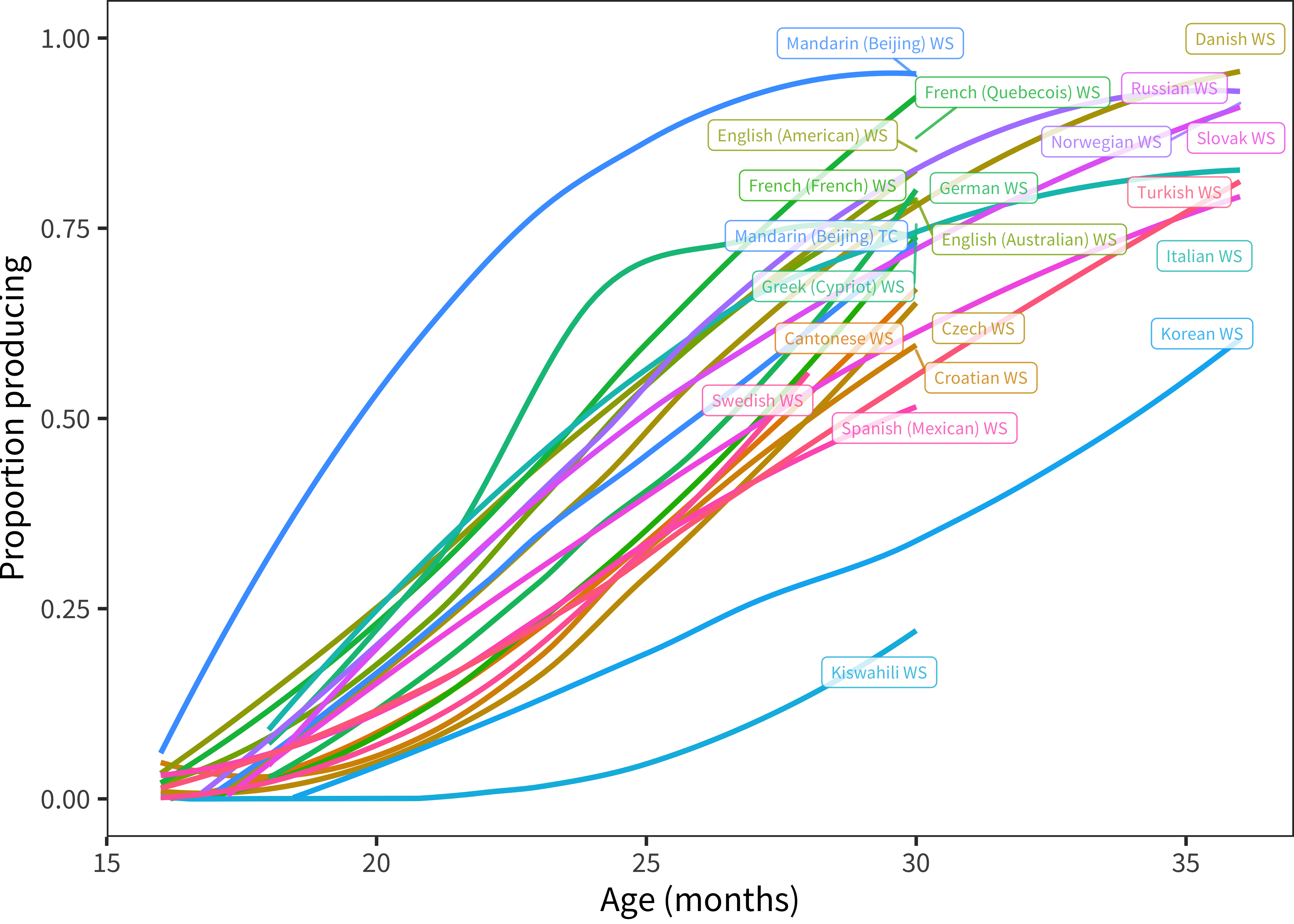
Figure 12.10: Mean developmental trajectory of color words in each language.
We additionally see an ordering across languages with respect to total rates of color word production reported (Figure 12.10). As in other analyses (see Chapter 5), Mandarin WS has the highest level of production. American and Australian English also tend to have high levels of color word production. Interestingly, Kiswahili has by far the lowest level of color word production, perhaps related to the limited availability of manufactured toys of contrastive colors (Bornstein 1985).
12.3.3 Body parts
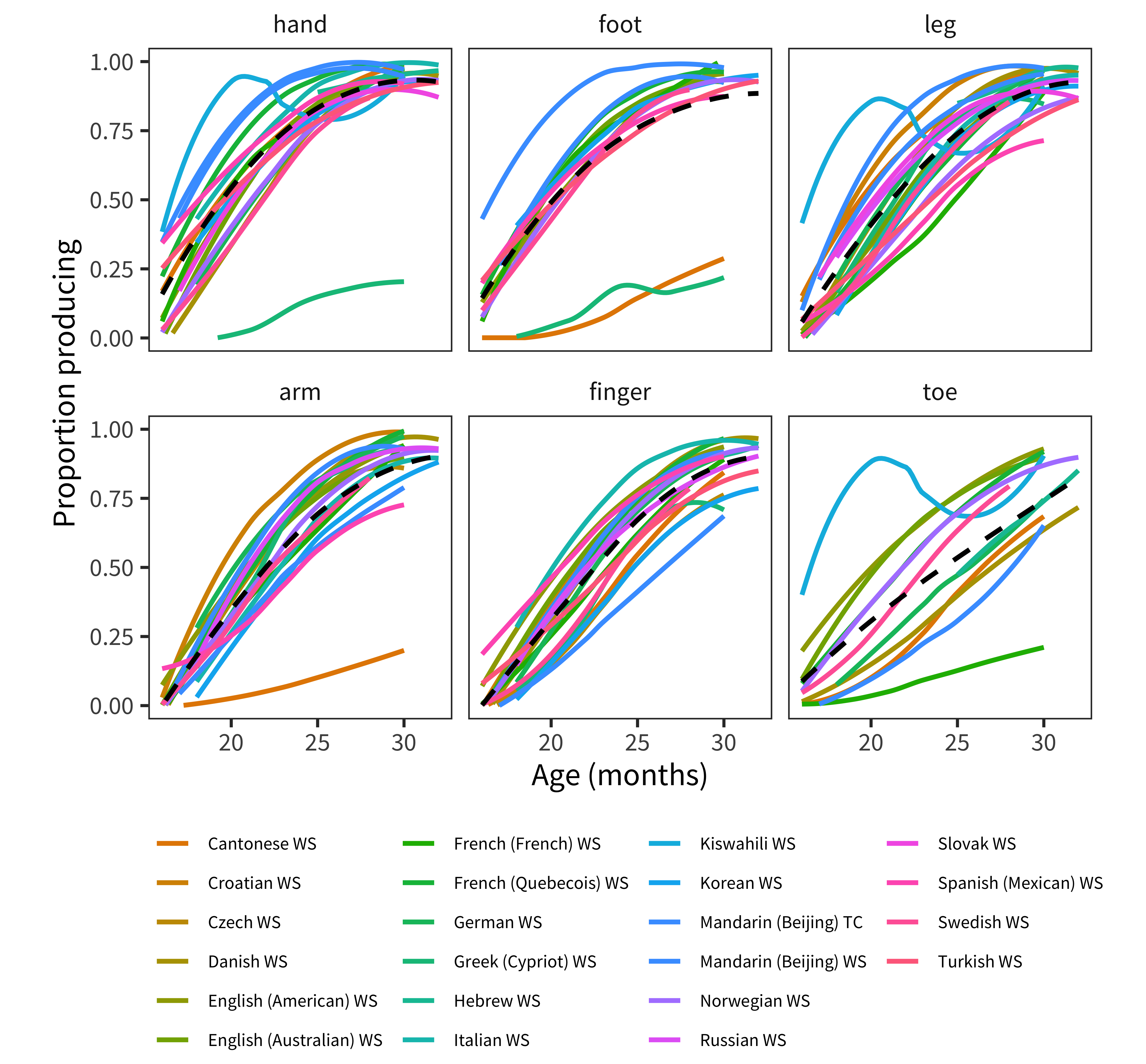
Figure 12.11: Developmental trajectory of each body part word in each language.
Across languages, body parts have been claimed as lexical universals: that is, nearly every language provides terms for naming the body (Andersen 1978). Despite this consistency, there is substantial cross-linguistic variation in exactly which body parts are named, reflecting different segmentation of body forms (e.g., some languages name both hand and arm while others have a single word for both) (Majid 2010). In our data, Words for Body Parts (Figure 12.11) are produced very early by most children, and the variance is quite low across languages (with the exception of a few terms in Cantonese and Cypriot Greek). One interesting pattern that is visible in these data is the ordering of hand and foot before leg and arm. Cantonese is probably variant here because hand and leg are monomorphemic (and written with single characters) while foot and arm in Cantonese are morphological compounds.
12.3.4 Logic
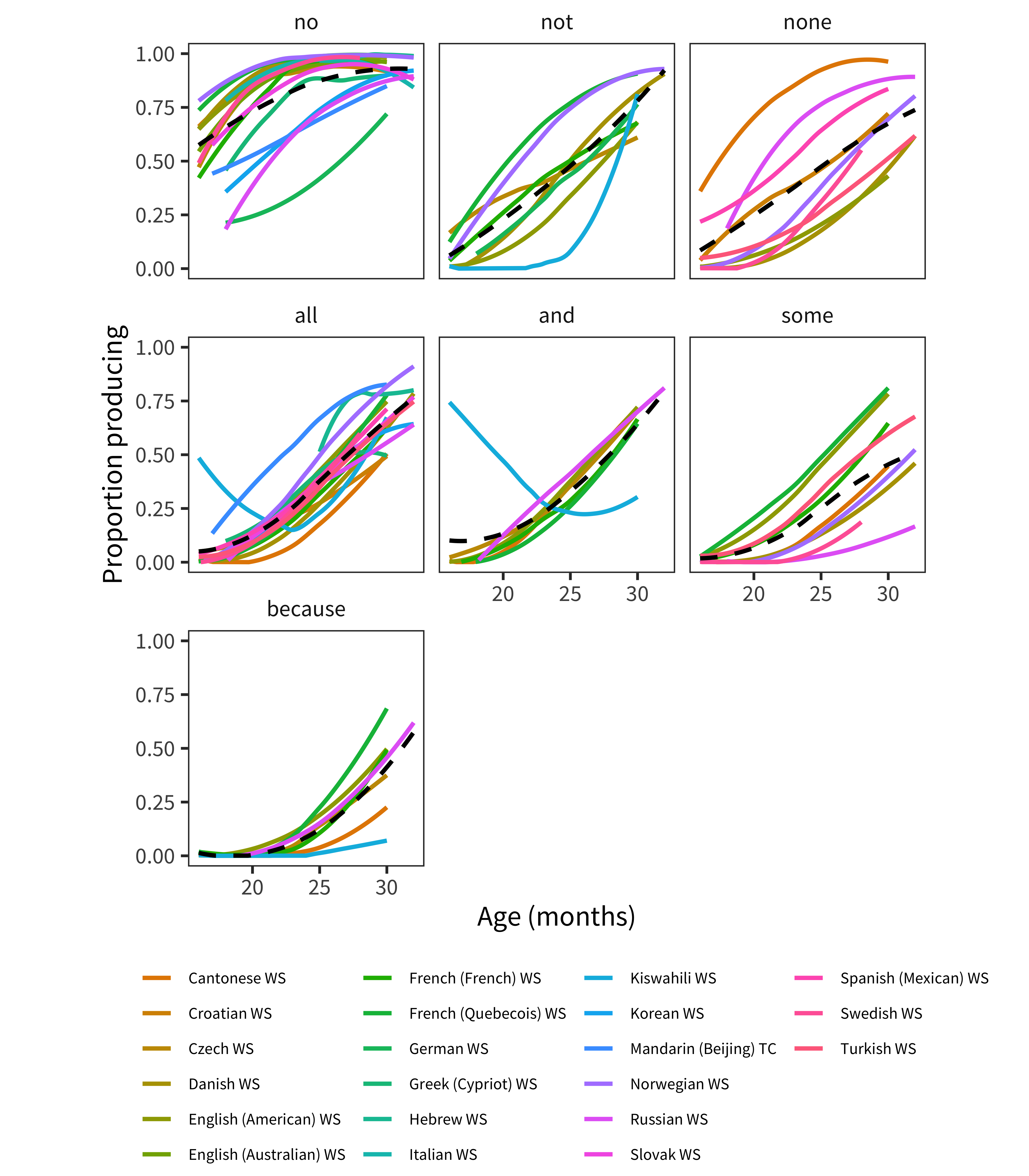
Figure 12.12: Developmental trajectory of each logic word in each language.
Finally, we examine words for logical operators (Figure 12.12). The only items that are available across significant samples of languages are all, and, because, none, some, no, not. One important caveat that applies especially here (although of course to other words as well) is that children may produce many of these words with meanings that are quite different from those they take in adult language. To take just one example, there is a large literature investigating the semantics and pragmatics of “some” in children’s language (see e.g., Barner, Brooks, and Bale 2011).
Keeping this caveat in mind, negative words are learned early, with an ordering consistent with Bellugi (1967) and Pea (1982). No is very early, and not later. Interestingly, the quantifiers are not ordered as shown by Katsos et al. (2016) in a massive cross-linguistic study. In that study – as well as in our own work in English (Horowitz, Schneider, and Frank 2017) – all was found to be understood better than none. In contrast, here we tend to find none is learned earlier than all and definitely learned earlier than some. One possibility is that these uses are only found in a restricted set of cases. Another is that contextualized production of negation is simpler than de-contextualized comprehension, as we have found in some of our work on the comprehension of negation in context (Nordmeyer and Frank 2014, 2018).
12.3.5 Category variability
To end this section, we quantify the variability across languages for each of these restricted sets of lexical items.23 For 22–26 month-olds (chosen somewhat arbitrarily to be an age range of high coverage across forms that does not encompass too much developmental change), we compute the coefficient of variation for children at each age on each lexical item (see Chapter 5 for the details of this analysis). (We first average across ages and then across lexical items; reported Ns are for the average number of contributing languages). We additionally add words from the Animals category for the sake of comparison. Table 12.1 gives the coefficient of variation for each category.
| Category | CV | SEM | N |
|---|---|---|---|
| Animals | 0.32 | 0.06 | 17.78 |
| Body | 0.27 | 0.05 | 16.50 |
| Color | 0.47 | 0.09 | 14.83 |
| Logic | 0.47 | 0.11 | 10.57 |
| Time | 0.53 | 0.09 | 16.44 |
This analysis shows that the acquisition of animal and body words is highly consistent across languages. In contrast, color words, logic words, and time words are substantially less consistent cross-linguistically. These effects are likely somewhat affected by floor and ceiling effects, but inspection of individual items confirms the robustness of the general conclusion.
12.4 Discussion
In these exploratory analyses, we considered representation of different semantic categories across the different languages in our dataset. We found some surprising consistencies. Words from the Places to Go and Words About Time categories were under-represented, while words from the Sounds, Games & Routines, and Body Parts categories were over-represented. These results converge with our analyses in Chapter 8 in suggesting that there are certain semantic categories that are quite common in children’s earliest language, and with our analyses in Chapter 10 in suggesting that there may be specific domains that parents associate with small children.
The consistencies we observed were also contrasted with some areas of greater variability. For example, the preference for words from the Vehicles, Clothing, and Animals categories appeared to be a somewhat coherent dimension in our data, with many (northern) European languages higher on this dimension than non-European languages. Still, substantial caution is necessary in interpreting these results as the sample of non-European languages is small. Finally, we found that acquisition of complex conceptual words reflecting colors, time, and logical constructs was highly variable across languages. For these more complex conceptual domains, order of acquisition may depend on specific cultural practices that govern the use and teaching of these words (e.g., for color) or the linguistic structures of the target language (e.g., for logical words).
Such an assumption would not be warranted if we were considering languages with just a handful of color terms, in which the extension of a term like red would be much larger than in English.↩︎
We experimented with applying this approach to the broader set of lexical categories we investigated in the first part of this chapter, but were confounded by a particular property of the coefficient of variation. For those categories with very small mean bias, even if they had small variance, their CV was very high (simply because \(CV = \sigma/\mu\) and hence as \(\mu\) goes down, CV must go up). For this reason, we choose only categories with some bias. We expand on this limitation to the CV analysis in Chapter 16.↩︎