7 Models
learning goals
- Articulate a strategy for estimating experimental effects using statistical models
- Build intuitions about how classical statistical tests relate to linear regression models
- Explore variations of the linear model, including generalized linear models and mixed effects models
- Reason about tradeoffs and strategies for model specification, including the use of control variables
In the previous two chapters, we introduced concepts surrounding estimation of an experimental effect and inference about its relationship to the effect in the population. The tools we introduced there are for fairly specific research questions, and so are limited in their applicability. Once you get beyond the world of two-condition experiments in which each participant contributes one data point from a continuous measure, the simple \(t\)-test is not sufficient.
In some statistics textbooks, the next step would be to present a whole host of other statistical tests that are designed for other special cases. We could even show a decision-tree: you have repeated measures? Use Test X! Or categorical data? Use Text Y! Or three conditions? Use Test Z! But this isn’t a statistics book, and even if it were, we don’t advocate that approach. The idea of finding a specific narrowly-tailored test for your situation is part and parcel of the dichotomous NHST approach that we tried to talk you out of in the last chapter. If all you want is your \(p<.05\), then it makes sense to look up the test that can allow you to compute a \(p\) value in your specific case. But we prefer an approach that is more focused on getting a good estimate of the magnitude of the causal effect.
In this chapter, we begin to explore how to select an appropriate statistical model to clearly and flexibly reason about these effects. A statistical model is a way of writing down a set of assumptions about how particular data are generated, the data generating process. Statistical models are the bread and butter tools for estimating particular parameters of interest from empirical data – like the magnitude of a causal effect associated with an experimental manipulation.
For example, suppose you watch someone tossing a coin and observe a sequence of heads and tails. A simple statistical model might assume that the observed data are generated via the flip of a weighted coin. From the perspective of the last two chapters, we could estimate a standard error for the estimated proportion of flips that are heads (e.g., for 6 heads out of 8 flips, we have \(\hat{p}= 0.75 \pm 0.17\)), or we could compare the observed proportion against a null hypothesis. From a model-based perspective, however, we instead begin by thinking about where the data came from: we might assume the coin being flipped has some weight (a latent, or unobservable, parameter of the data generating process), and our goal is to determine the most likely value of that weight given the observed data. This single unified model can then also be used to make inferences about whether the coin’s weight differs from some null model (a fair coin, perhaps), or to predict future flips.
This example sounds a lot like the kinds of simple inferential tests we talked about in the previous chapter; not very “model-y.” But things get more interesting when there are multiple parameters to be estimated, as in many real-world experiments. In the tea-tasting scenario we’ve belabored over the past two chapters, a real experiment might involve multiple people tasting different types of tea in different orders, all with some cups randomly assigned to be milk-first or tea-first. What we’ll learn to do in this chapter is to make a model of this situation that allows us to reason about the magnitude of the milk-order effect while also estimating variation due to different people, orders, and tea types. This is the advantage of using models: once you are able to reason about estimation and inference in model-based terms, you will be set free from long decision trees and will be able to flexibly make the assumptions that make sense for your data.1
1 We won’t explore the connection to DAGs and Bayesian models here, but one way to think of this model building is as creating a causal theory of the experiment. This approach, which is advocated by McElreath (2018), creates powerful connections between the ideas about theory we presented in Chapters 1 and 7 and the ideas about models here. If this sounds intriguing, we encourage you to go down the rabbit hole!
We’ll begin by discussing the ubiquitous framework for building statistical models, linear regression.2 We will then build connections between regression and the \(t\)-test. This section will discuss how to add covariates to regression models, and when linear regression does and doesn’t work. In the following section, we’ll discuss the generalized linear model, an innovation that allows us to make models of a broader range of data types, including logistic regression. We’ll then briefly introduce mixed models, which allow us to model clustering in our datasets (such as clusters of observations from a single individual or single stimulus item). We’ll end with some opinionated practical advice on model building.
2 The name regression originally comes from Galton (1877)’s work on heredity. He was looking at the relationship between the heights of parents and children. He found that children’s heights regressed, and he did so by creating a regression model. Now we use the term “regression” to mean any model of this form.
If you’re interested in building up intuitions about statistical model building, then we recommend reading this chapter all the way through. On the other hand, if you are already engaged in data analysis and want to see an example, we suggest that you skip to the last section, where we give some opinionated practical advice on model building and provide a worked example of fitting a mixed effects model and interpreting it in context.
7.1 Regression models
There are many types of statistical models, but this chapter will focus primarily on regression, a broad and extremely flexible class of models. A regression model relates a dependent variable to one or more independent variables. Dependent variables are sometimes called outcome variables, and independent variables are sometimes called predictor variables, covariates, or features.3 We will see that many common statistical estimators (like the sample mean) and methods of inference (like the \(t\)-test) are actually simple regression models. Understanding this point will help you see many statistical methods as special cases of the same underlying framework, rather than as unrelated, ad hoc tests.
3 The reverse is not true – not every predictor or covariate is an independent variable! One of the tricky things about relating regression models to causal hypotheses is that, just because something is on the right side of a regression equation, that doesn’t mean it’s a causal manipulation. And of course, just because you’ve got an estimate of some predictor in a regression, that doesn’t mean the estimate tells you about the magnitude of the causal effect. It could, but it also might not!
7.1.1 Regression for estimating a simple treatment effect
Let’s start with one of these special cases, namely estimating a treatment effect, \(\beta\), in a two-group design. In Chapter 5, we solved this exact challenge for the tea-tasting experiment. We applied a classical model in which the milk-first ratings are assumed to be normally distributed with mean \(\theta_{\text{<}} = \theta_{\text{T}} + \beta\) and standard deviation \(\sigma\).4
4 Here’s a quick reminder that “model” here is a way of saying “set of assumptions about the data generating procedure.” So saying that some equation is a “model” is the same as saying that we think this is where the data came from. We can “turn the crank” – generate data through the process that’s specified in those equations, e.g., pulling numbers from a normal distribution with mean \(\theta_{\text{M}}\) and standard deviation \(\sigma\). In essence, we’re committing to the idea that this process will give us data that are substantively similar to the ones we have already.
Let’s now write that model as a regression model, that is, as a model that predicts each participant’s tea rating, \(Y_i\), given that participant’s treatment assignment, \(X_i\). \(X_i=0\) represents the control (milk-first) group and \(X_i=1\) represents the treatment (tea-first) group.5 Here, \(Y_i\) is the dependent variable, and \(X_i\) is the independent variable. The subscripts \(i\) index the participants. To make this concrete, you can see some sample tea-tasting data (the first six observations from each condition) below (Table 7.1), with the index \(i\), the condition and its predictor \(X_i\), and the rating \(Y\).
5 Using 0 and 1 is known as dummy coding, and allows us to interpret the parameter as the difference of the treatment group (tea-first) from the baseline (milk-first). There are many other ways to code categorical variables, with other interpretations. As a practical tip, be careful to check how your variables are coded before reporting anything!
| id | condition | X | rating (Y) |
|---|---|---|---|
| 1 | milk first | 0 | 6 |
| 2 | milk first | 0 | 4 |
| 3 | milk first | 0 | 5 |
| 4 | milk first | 0 | 5 |
| 5 | milk first | 0 | 5 |
| 6 | milk first | 0 | 4 |
| 7 | tea first | 1 | 1 |
| 8 | tea first | 1 | 5 |
| 9 | tea first | 1 | 3 |
| 10 | tea first | 1 | 1 |
| 11 | tea first | 1 | 3 |
| 12 | tea first | 1 | 5 |
Let’s write this model more formally as a linear regression of Y on X. Conventionally, regression models are written with “\(\beta\)’’ symbols for all parameters, so we’ll now use \(\beta_0 = \theta_M\) for the mean in the milk-first group and \(\beta_1 = \theta_T - \theta_M\) as the average difference between the tea-first and milk-first groups.6
6 This \(\beta\) is a generalization of the one were using to denote the causal effect above and in the previous two chapters.
\[ Y_i = \beta_0 + \beta_1 X_i + \epsilon_i \]
The term \(\beta_0 + \beta_1 X_i\) is called the linear predictor, and it describes the expected value of an individual’s tea rating, \(Y_i\), given that participant’s treatment group \(X_i\) (the single independent variable in this model). That is, for a participant in the control group (\(X_i=0\)), the linear predictor is just equal to \(\beta_0\), which is indeed the mean for the control group that we specified above. On the other hand, for a participant in the treatment group, the linear predictor is equal to \(\beta_0 + \beta_1\), which is the mean for the treatment group that we specified. In regression jargon, \(\beta_0\) and \(\beta_1\) are regression coefficients, where \(\beta_1\) represents the association of the independent variable \(X\) with the outcome \(Y\).
The term \(\epsilon_i\) is the error term, referring to random variation of participants’ ratings around the group mean.7 Note that this is a very specific kind of “error”; it does not include “error” due to bias, for example. Instead, you can think of the error terms as capturing the “error” that would be associated with predicting any given participant’s rating based on just the linear predictor. If you predicted a control group participant’s rating as \(\beta_0\), that would be a good guess – but you still expect the participant’s rating to deviate somewhat from \(\beta_0\) (i.e., due to variability across participants beyond what is captured by their treatment groups). In our regression model, the linear predictor and error terms together say that participants’ ratings scatter randomly (in fact, normally) around their group means with standard deviation \(\sigma\). And that is exactly the same model we posited in Chapter 5.8
7 Formally, we’d write \(\epsilon_i \sim \mathcal{N}(0, \sigma^2)\). The tilde means “is distributed as”, and what follows is a normal distribution with mean 0 and variance \(\sigma^2\).
8 You may be wondering why so much effort was put into building boutique solutions for these special cases when a unified framework was available the whole time. A partial answer is that the classical infrastructure of statistics was developed before computers were widespread, and these special cases were chosen because they were easy to work with “analytically” (meaning to work out all the math with pen-and-paper, using values from big numerical tables). Now that we have computers with more flexible algorithms, the model-based perspective is more practical and accessible than it used to be.
Now we have the model. But how do we estimate the regression coefficients \(\beta_0\) and \(\beta_1\)? The usual method is called ordinary least squares (OLS). Here’s the basic idea. For any given regression coefficient estimates \(\widehat{\beta}_0\) and \(\widehat{\beta}_1\), we would obtain different predicted values, \(\widehat{Y}_i = \widehat{\beta}_0 + \widehat{\beta}_1 X_i\) for each participant. Some regression coefficient estimates will yield better predictions than others. OLS estimation is designed to find the values of the regression coefficients that optimize these predictions, meaning that the predictions are as close as possible to participants’ true outcomes, \(Y_i\).9
9 Specifically, OLS minimizes squared error loss, in the sense that it will choose the regression coefficient estimates whose predictions minimize \(\sum_{i=1}^n \left( Y_i - \widehat{Y}_i\right)^2\), where \(n\) is the sample size. A wonderful thing about OLS is that those optimal regression coefficients (generically termed \(\widehat{\mathbf{\beta}}\)) turn out to have a very simple closed form solution: \(\widehat{\mathbf{\beta}} = \left( \mathbf{X}'\mathbf{X} \right)^{-1} \mathbf{X}'\mathbf{y}\). We are using more general notation here that supports multiple independent variables: \(\widehat{\mathbf{\beta}}\) is a vector, \(\mathbf{X}\) is a matrix of independent variables for each subject, and \(\mathbf{y}\) is a vector of participants’ outcomes. As more good news, the standard error for \(\widehat{\mathbf{\beta}}\) has a similarly simple closed form!
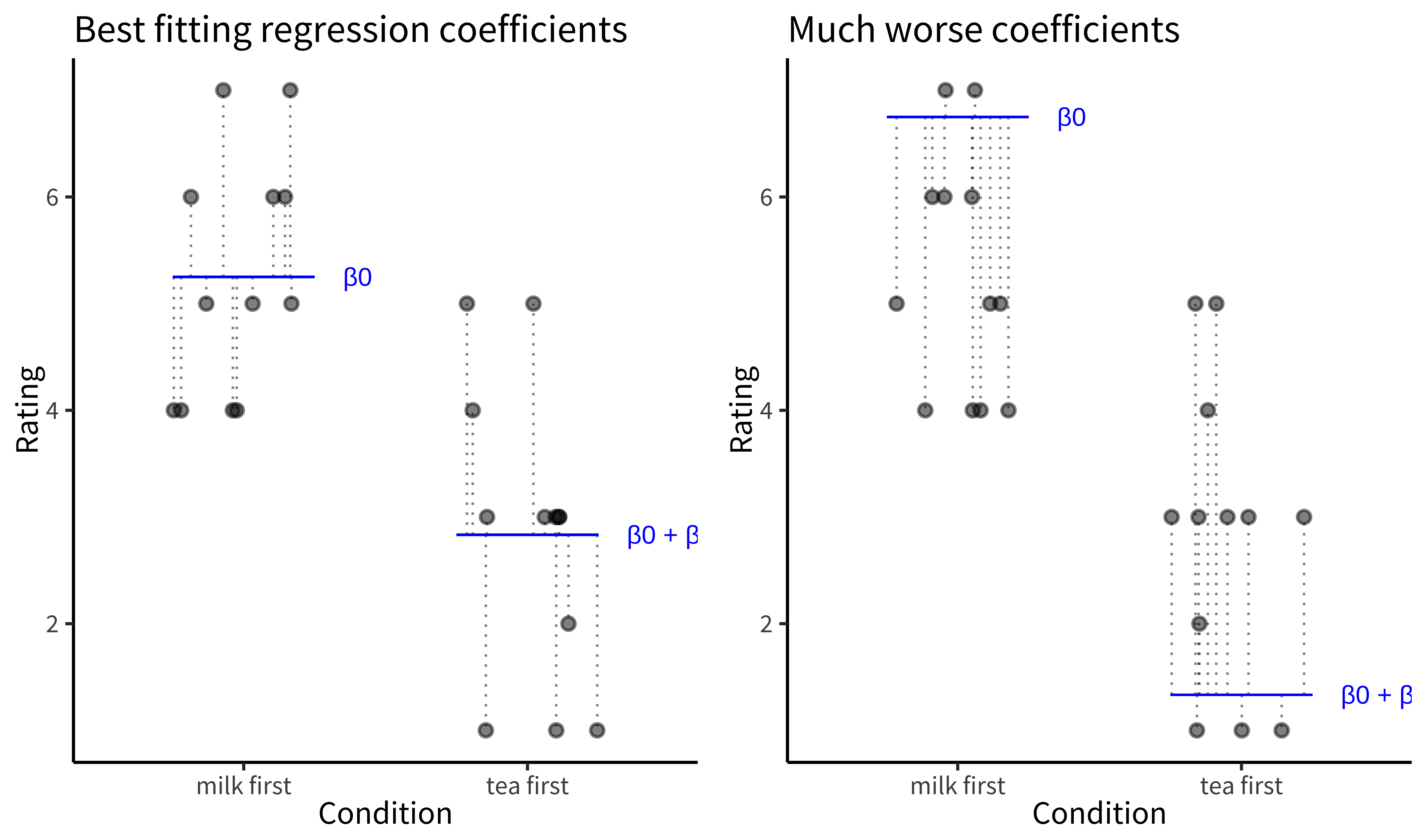
- illustrates the tea tasting data for each condition (the dots) along with the model predictions for each condition \(\beta_0\) and \(\beta_0 + \beta_1\) (blue lines). The gap between each data point and the corresponding predictions (the thing that OLS wants to minimize) is shown by the dotted lines. These distances are sample estimates, called residuals, of the true errors (\(\epsilon_i\). The left-hand plot shows the OLS coefficient values – the ones that move the model’s predictions as close as possible to the data points, in the sense of minimizing the total squared length of the dashed lines. The right-hand plot shows a substantially worse set of coefficient values.
code
As it turns out, fitting an OLS regression model in R is extremely easy. The underlying call is lm, which stands for linear model. You can fit the model with a single call to this function with a “formula” as its argument. Here’s the call:
mod <- lm(rating ~ condition, data = tea_data)Formulas in R are a special kind of terse notation for regression equations where you write the outcome, ~ (distributed as), and the predictors. R assumes that you want an intercept by default, and there are also a number of other handy defaults that make R formulas a nice easy way to specify relatively complex regression models, as we’ll see below.
Once you’ve fit the model and assigned it to a variable, you can call summary to see a summary of the parameters of the model:
summary(mod)You can also extract the coefficient values using coef(mod), and put them in a handy dataframe using tidy(mod) from the broom package.
You’ll notice that we aren’t talking much about \(p\)-values in this chapter. Regression models can be used to produce \(p\)-values for specific coefficients, representing inferences about the likelihood of the observed data under some null hypothesis regarding the coefficients. You can also compute Bayes Factors for specific regression coefficients, or use Bayesian inference to fit these coefficients under some prior expectation about their distribution. We won’t talk much about this, or more generally how to fit the models we describe. As we said, we’re not going to give a full treatment of all the relevant statistical topics. Instead we want to help you begin thinking about making models of your data.
7.1.2 Adding predictors
The regression model we just wrote down is the same model that underlies the \(t\)-test from Chapter 6. But the beauty of regression modeling is that much more complex estimation problems can also be written as regression models that extend the model we made above. For example, we might want to add another predictor variable, such as the age of the participant.10
10 The ability to estimate multiple coefficients at once is a huge strength of regression modeling, so much so that sometimes people use the label multiple regression to denote that there is more than one predictor + coefficient pair.
Let’s add this new independent variable and a corresponding regression coefficient to our model:
\[ Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \epsilon_i \]
Now that we have multiple independent variables, we’ve labeled them \(X_{1}\) (treatment group) and \(X_{2}\) (age) for clarity.
To illustrate how to interpret the regression coefficients in this model, let’s use the linear predictor to compare the model’s predicted tea ratings for two hypothetical participants who are both in the treatment group: 20-year-old Alice and 21-year old Bob. Alice’s linear predictor tells us that her expected rating is \(\beta_0 + \beta_1 + \beta_2 \cdot 20\). In contrast, Bob’s linear predictor is \(\beta_0 + \beta_1 + \beta_2 \cdot 21\). We could therefore calculate the expected difference in ratings for 21-year-olds versus 20-year olds by subtracting Alice’s linear predictor from Bob’s, yielding just \(\beta_2\).
We would get the same result if Alice and Bob were instead 50 and 51 years old, respectively. This equivalence illustrates a key point about linear regression models in general:
The regression coefficient represents the expected difference in outcome when comparing any two participants who differ by 1 unit of the relevant independent variable, and who do not differ on any other independent variables in the model.
Here, the coefficient compares participants who differ by 1 year of age. In “Practical modeling considerations” below, we discuss whether and when to “control for” additional variables (i.e., when to add them to your model).
7.1.3 Interactions
In our running example, we now have two predictors: condition and age. But what if the effect of condition varies depending on the age of the participant? This situation would correspond to a case where (say) older people were more sensitive to tea ordering, perhaps because of their greater tea experience. We call this an interaction effect: the effect of one predictor depends on the state of another.
Interaction effects are easily accommodated in our modeling framework. We simply add a term to our model that is the product of condition (\(X_1\)) and age (\(X_2\)), and weight this product by another beta, which represents the strength of this interaction:
\[ Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \beta_3 X_{i1} X_{i2} + \epsilon_i \] Statistical interactions are a very powerful modeling tool that can help us understand the relationship between different experimental manipulations or between manipulations and covariates (such as age). We discuss their role in experimental design – as well as some of the interpretive challenges that they pose – in much more detail in Chapter 9.11
11 We won’t go into this topic here, but we do want to provide a pointer to one of the most persistent challenges that come up when you specify regression models with categorical predictors – and especially their interactions: how you “code” these categorical predictors. Above we created a variable \(X\) that encoded milk-first tea as 0 and tea-first tea as 1. This coding system is known as dummy coding, because \(X\) is a “dummy” variable that stands in for milk-first tea. Dummy variables are very easy to think about, but in models with interactions, they can cause some problems. Because the interaction in our example model is a product of the dummy-coded condition variable and age, the interaction term \(\beta_3\) is interpreted as the effect of age for the tea-first condition (\(X=1\)) and hence the effect of age \(\beta_2\) is actually the effect of age for the milk-first condition. The way to deal with this issue is to use a different coding system, such as contrast coding. Davis (2010) gives a good tutorial on this tricky topic.
7.1.4 When does linear regression work?
Linear regression modeling with OLS is an incredibly powerful technique for creating models to estimate the influence of multiple predictors on a single dependent variable. In fact, OLS is in a mathematical sense the best way to fit a linear model!12 But OLS only “works” – in the sense of yielding good estimates – if three big conditions are met.
12 There is a precise sense in which OLS gives the very best predictions we could ever get from any model that posits linear relationships between the independent variables and the outcome. That is, you can come up with any other linear, unbiased model you want, and yet if the assumptions of OLS are fulfilled, predictions from OLS will always be less noisy than those of your model. This is because of an elegant mathematical result called the Gauss-Markov Theorem.
- The predictor relationships being modeled must be linear. In our comparison of Alice’s and Bob’s expected outcomes based on their 1-year age difference, we were able to interpret the coefficient \(\beta_2\) as the average difference in \(Y_i\) when comparing participants who differ by 1 year of age, regardless of whether those ages are 20 vs. 21 or 50 vs. 51. But that’s not always true: plenty of things vary non-linearly with age – for example, imagine growth in height over age! Linear regression will give bad answers in such cases.13
13 One way to accommodate non-linearities is to modify the linear predictor to include polynomial terms, such as \(X_2^2\), which then allow us to fit a curve rather than just a straight line. It is always a good idea to use visualizations like scatter plots to look for possible problems with linearity.
- Errors must be independent. In our example, observations in the regression model (i.e., rows in the dataset) were sampled independently: each participant was recruited independently to the study and each performed a single trial. On the other hand, suppose we have repeated-measures data in which we sample participants, and then obtained multiple measurements for each participant. Within each participant, measurements would likely be correlated (perhaps because participants differ on their general level of tea enjoyment). This correlation can invalidate inferences from a model that does not accommodate the correlation. We’ll discuss this problem in detail below.
- Errors must be normally distributed and unrelated to the predictor. Imagine older people have very consistent tea-ordering preferences while younger people do not. In that case, the models’ error term would be less variable for older participants than younger ones. This issue is called heteroskedasticity. It is a good idea to plot each independent variable versus the residuals to see if the residuals are more variable for certain values of the independent variable than for others.
If any of these three conditions are violated, it can undermine the estimates and inferences you draw from your model.
7.2 Generalized linear models
So far we have considered continuous outcome measures, like tea ratings. What if we instead had a binary outcome, such as whether a participant liked or didn’t like the tea, or a count outcome, such as the number of cups a participant chose to drink? These and other non-continuous outcomes often violate the assumptions of OLS, in particular because they often induce heteroskedastic errors.
Binary outcomes inherently produce heteroskedastic errors because the variance of a binary variable depends directly on the outcome probability. Errors will be more variable when the outcome probability is closer to 0.50, and much less variable for when the probability is closer to 0 or 1.14 This heteroskedasticity in turn means that inferences from the model (e.g., \(p\)-values) can be incorrect; sometimes just a little bit off but sometimes dramatically incorrect.15
14 Specifically, the variance of a binary variable with probability \(p\) is simply \(p(1-p)\), which is largest when \(p=0.50\).
15 OLS can also be used with binary outcomes, in which case the coefficients represent differences in probabilities. However, the usual model-based standard errors will be incorrect.
Happily, generalized linear models (GLMs) are regression models closely related to OLS that can handle non-continuous outcomes. These models are called “generalized” because OLS is one of many members of this large class of models. To see the connection, let’s first write an OLS model more generally in terms of what it says about the expected value of the outcome, which we notate as \(E[Y_i]\):
\[ E[Y_i] = \beta_0 + \sum_{j=1}^p \beta_j X_{ij} \]
where \(p\) is the number of independent variables, \(\beta_0\) is the intercept, and \(\beta_j\) is the regression coefficient for the \(j^{th}\) independent variable. This equation is just a math-y way of saying that you predict from a regression model by adding up each of the predictors’ contributions to the expected outcome (\(\beta_j X_{ij}\)).
The linear predictor of a GLM (i.e., \(\beta_0 + \sum_{j=1}^p \beta_j X_{ij}\)) looks exactly the same as for OLS, but instead of modeling \(E[Y_i]\), a GLM models some transformation, \(g(.)\), of the expectation:
\[ g( E[Y_i] ) = \beta_0 + \sum_{j=1}^p \beta_j X_{ij} \]
GLMs involve transforming the expectation of the outcome, not the outcome itself! That is, in GLMs, we are not just taking the outcome variable in our dataset and transforming it before fitting an OLS model, but rather we are fitting a different model entirely, one that posits a fundamentally different relationship between the predictors and the expected outcomes. This transformation is called the link function. In other words, to fit different kinds of outcomes, all we need to do is construct a standard linear model and then just transform its output via the appropriate link function.
Perhaps the most common link function is the logit link, which is suitable for binary data. This link function looks like this, where \(w\) is any probability that is strictly between 0 and 1:
\[g(w) = \log \left( \frac{w}{1 - w} \right)\]
The term \(w / (1 - w)\) is called the odds and represents the probability of an event occurring divided by the probability of its not occurring. The resulting model is called logistic regression and looks like:
\[ \text{logit}( E[Y_{it}] ) = \log \left( \frac{ E[Y_i] }{1 - E[Y_i] } \right) = \beta_0 + \sum_{j=1}^p \beta_j X_{ij} \]
Exponentiating the coefficients (i.e., \(e^{\beta}\)) would yield odds ratios, which are the multiplicative increase in the odds of \(Y_i=1\) that is associated with a one-unit increase in the relevant predictor variable.
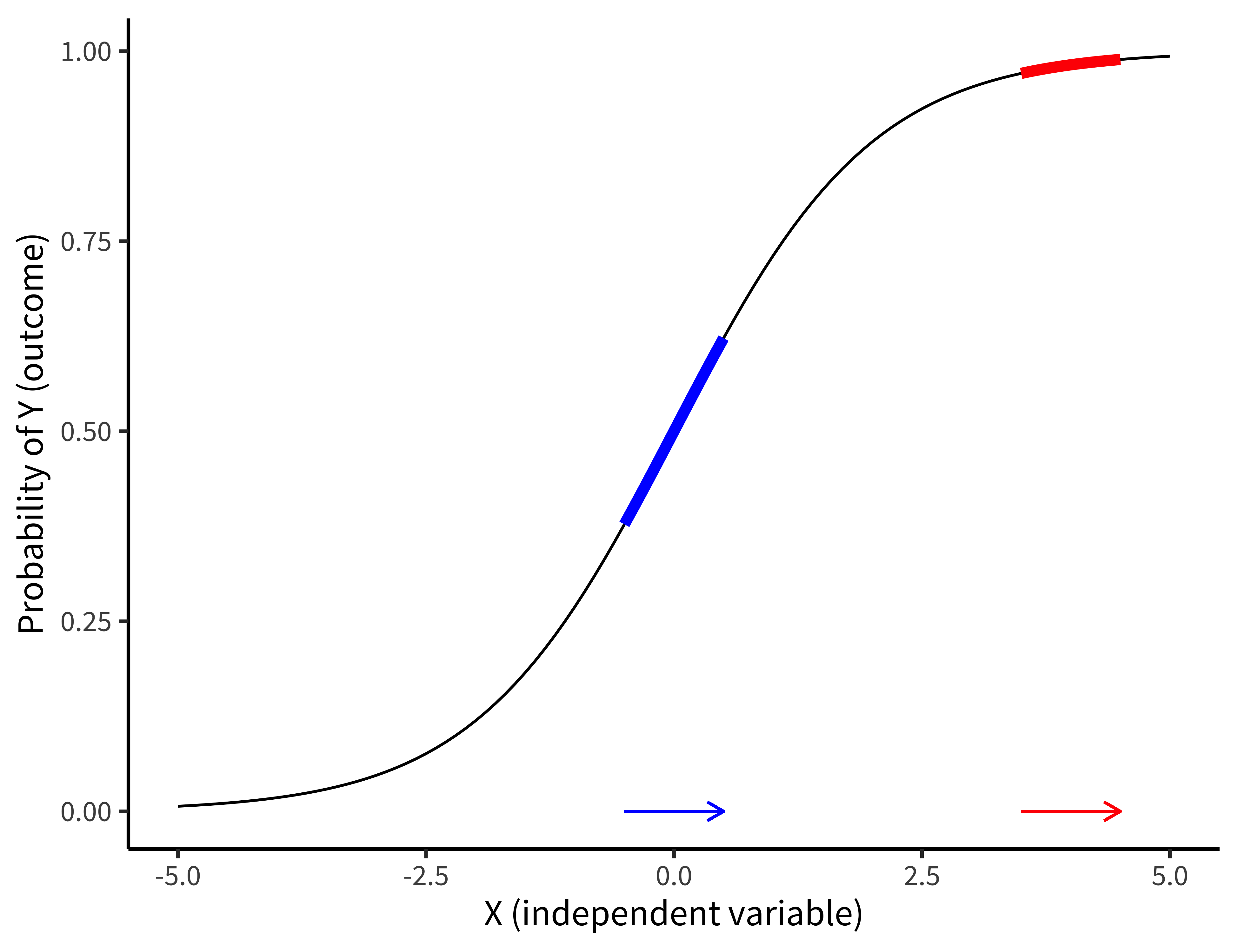
Figure 7.2 shows the way that a logistic regression model transforms a predictor (\(X\)) into an outcome probability that is bounded at 0 and 1. Critically, although the predictor is still linear, the logit link means that the same change in \(X\) can result in a different change in the absolute probability of \(Y\) depending on where you are on the \(X\) scale. In this example, if you are in the middle of the predictor range, a one-unit change in \(X\) results in a 0.24 change in probability (blue). At a higher value, the change is much smaller (0.02. Notice how this is different from the linear regression model above, where the same change in age always resulted in the same change in preference!
code
GLMs are as easy to fit in R as standard LMs. You simply need to call the glm function – and to specify the link function. For our example above of a binary “liking” judgment, the call would be:
glm(liked_tea ~ condition, data = tea_data, family = "binomial")The family argument specifies the type of distribution being used, where “binomial” is the logistic link function.
We have only scratched the surface of GLMs here. First, there are many different link functions that are suitable for different outcome types. And second, GLMs differ from OLS not only in their link functions, but also in how they handle the error terms. Our broader goal in this chapter is to show you how regression models are models of data. In that context, GLMs use link functions as a way to make models that generate many different times types of outcome data.16
16 We sometimes think of linear models as a set of tinker toys you can snap together to stack up a set of predictors. In that context, link functions are an extra “attachment” that you can snap onto your linear model to make it generate a different response type.
7.3 Linear mixed effects models
Experimental data often contain multiple measurements for each participant (so-called repeated measures). In addition, these measurements are often based on a sample of stimulus items (which then each have multiple measures as well). This clustering is problematic for OLS models, because the error terms for each datapoint are not independent.
Non-independence of datapoints may seem at first glance like a small issue, but it can present a deep problem for making inferences. Take the tea-tasting data we looked at above, where we had 24 observations in each condition. If we fit an OLS model, we observe a highly significant tea-first effect. Here is the estimate and confidence interval for that coefficient: \(b = -2.42\), 95% CI \([-3.50, -1.33]\). Based on what we talked about in the previous chapter, it seems like we’d be licensed in rejecting the null hypothesis that this effect is due to sampling variation and interpret this instead as evidence for a generalizable difference in tea preference in our sampled population.
But suppose we told you that all of those 48 total observations (24 in each condition) were from one individual named George. That would change the picture considerably. Now we’d have no idea whether the big effect we observed reflected a difference in the population, but we would have a very good sense of what George’s preference is!17 The confidence intervals and p-values from our OLS model would be wrong now because all of the error terms would be highly correlated – they would all reflect George’s preferences.
17 We discuss the strengths and weaknesses of repeated-measures designs like this in Chapter 9 and the statistical tradeoffs of having many people with a small number of observations per person vs. a small number of people with many observations per person in Chapter 10.
How can we make models that deal with clustered data? There are a number of widely-used approaches for solving this problem including linear mixed effects models, generalized estimating equations, and clustered standard errors (often used in economics). Here we will illustrate how the problem gets solved in linear mixed models, which are an extension of OLS models that are fast becoming a standard in many areas of psychology (Bates et al. 2014).
7.3.1 Modeling random variation in clusters
In linear mixed effects models, we modify the linear predictor itself to model differences across clusters. Instead of just measuring George’s preferences, suppose we modified the original tea-tasting experiment (without the age covariate) to collect ten ratings from each participant: five milk-first and five tea-first. We define the model the same way as we did before, with some minor differences:
\[ Y_{it} = \beta_0 + \beta_1 X_{it} + \gamma_i + \epsilon_{it} \]
where \(Y_{it}\) is participant \(i\)’s rating in trial \(t\) and \(X_{it}\) is the participant’s assigned treatment in trial \(t\) (i.e., milk-first or tea-first).
If you compare this equation to the OLS equation above, you will notice that we added two things. First, we’ve added subscripts that distinguish trials from participants. But the big one is that we added \(\gamma_i\), a separate intercept value for each participant. We call this a random intercept because it varies across participants (who are randomly selected from the population).18
18 Formally, we’d notate this random variation by saying that \(\gamma_i \sim N(0, \tau^2)\) – in other words, that participants’ random intercepts are sampled from a normal distribution around the shared intercept \(\beta_0\) with standard deviation \(\tau\).
The random intercept means that we have assumed that each participant has their own typical “baseline” tea rating – some participants overall just like tea more than others – and these baseline ratings are normally distributed across participants. Thus, ratings are correlated within participants because ratings cluster around each participant’s distinct baseline tea rating. This model is better able to block misleading inferences. For example, suppose we only had one participant in each condition (say, George provided 24 milk-first ratings and Alice provided 24 tea-first ratings). If we found higher ratings in one condition, we would be able to attribute this difference to participant-level variation rather than to the treatment.19
19 Of course, this would be a terrible experiment! Ideally, we would address this problem upstream in our experiment design; see Chapter 9.
Following the same logic, we could fit random intercepts for different stimulus items (for example, if we used different types of tea for different trials). We modeled participants as having normally distributed variation, and we can model stimulus variation the same way. Each stimulus item is assumed to produce a particular average outcome (i.e. some teas are tastier than others), with these average outcomes sampled from a normally distributed population.
code
Remarkably, GLMMs are not much harder to specify in R than standard LMs. One very popular package is lme4 (Bates et al. 2014), which provides the lmer and glmer functions (the latter for generalized linear mixed effect models). For our example here, we’d write:
library(lme4)
lmer(rating ~ condition + (1 | id), data = tea_data)In this model, the syntax (1 | id) specifies that we want a random intercept for each level of id.
7.3.2 Random slopes and the challenges of mixed effects models
Linear mixed effects models can be further extended to model clustering of the independent variables’ effects within subjects, not just clustering of average outcomes within subjects. To do so, we can introduce random slopes (\(\delta_i\)) to the model, which are multiplied by the condition variable \(X\) and represent differences across participants in the effect of tea-tasting:
\[ Y_i = \beta_0 + \beta_1 X_{it} + \gamma_i + \delta_{i} X_{it} + \epsilon_{it} \]
Just like the random intercepts, these random slopes will be assumed to vary across participants, following a normal distribution.20
20 These random slopes and intercepts can be assumed to be independent or correlated with one another, depending on the modeler’s preference.
This model now describes random variation in both overall how much someone likes tea and how strong their ordering preference is. Both of these likely do vary in the population and so it seems like a good thing to put these in your model. Indeed under some circumstances, adding random slopes is argued to be very important for making appropriate inferences.21
21 There’s lots of debate in the literature about the best random effect structure for mixed effects models. This is a very tricky and technical subject. In brief, some folks argue for so-called maximal models, in which you include every random effect that is justified by the design (Barr et al. 2013). Here that would mean including random slopes for each participant. The problem is that these models can get very complex, and can be very hard to fit using standard software. We won’t weigh in on this topic, but as you start to use these models on more complex experimental designs, it might be worth reading up.
On the other hand, the model is much more complicated. When we had a simple OLS model above, we had only two parameters to fit (\(\beta_0\) and \(\beta_1\)) but now we have those two plus two more, representing the standard deviations of the individual participant intercepts and slopes, plus parameters for each participant and for the condition effect for each participant. So we went from two parameters to 24!22 This complexity can lead to problems in fitting the models, especially with very small datasets (where these parameters are not very well-constrained by the data) or very large datasets (where computing all these parameters can be tricky).23
22 Though we should note that these parameters aren’t technically all independent from one another due to the structure of the mixed effect model.
23 Many R users may be familiar with the widely-used lme4 package for fitting mixed effects models using frequentist tools related to maximum likelihood. Such models can also be fit using Bayesian inference with the brms package, which provides many powerful methods for specifying complex models.
More generally, linear mixed effects models are very flexible, and they have become quite common in psychology. But they do have significant limitations. As we discussed, they can be tricky to fit in standard software packages. Further, the accuracy of these models relies on our ability to specify the structure of the random effects correctly.24 If we specify an incorrect model, our inferences will be wrong! But it is sometimes difficult to know how to check whether your model is reasonable, especially with a small number of clusters or observations.
24 One particularly problematic situation is when the correlation structure of the errors is mis-specified, for example if observations within a participant are more correlated for participants in the treatment group than in the control group; in such cases, mixed model estimates can be substantially biased (Bie et al. 2021).
code
Specifying random slopes in the lme4 package is also relatively straightforward:
library(lme4)
lmer(rating ~ condition + (condition | id), data = tea_data)Here, (condition | id) means “a separate random slope for condition should be fit for each level of id.” Of course, specifying such a model is easier than fitting it correctly.
depth
An alternative approach: Generalized estimating equations
A second class of methods that helps resolve issues of clustering is generalized estimating equations (GEE). In this approach, we leave the linear predictor alone. We do not add random intercepts or slopes, nor do we assume anything about the distribution of the errors (i.e., we no longer assume that they are normal, independent, and homoskedastic).
In GEE, we instead provide the model with an initial “guess” about how we think the errors might be related to one another; for example, in a repeated-measures experiment, we might guess that the errors are exchangeable, meaning that they are correlated to the same degree within each participant but are uncorrelated across participants. Instead of assuming that our guess is correct, as do linear mixed models (LMM), GEE estimates the correlation structure of the errors empirically, using our guess as a starting point, and it uses this correlation structure to arrive at point estimates and inference for the regression coefficients. Remarkably, as the number of clusters and observations become very large, GEE will always provide unbiased point estimates and valid inference, even if our guess about the correlation structure was bad. Additionally, with simple finite-sample corrections (Mancl and DeRouen 2001), GEE seems to provide valid inference at smaller numbers of clusters than does LMM.
The price paid for these nice safeguards against model misspecification is that, in principle, GEE will typically have less statistical power than LMM if the LMM is in fact correctly specified, but the difference may be surprisingly slight in practice (Bie et al. 2021). For these reasons, some of this book’s authors actually favor GEE with finite-sample corrections over LMM as the default model for clustered data, though they are much less common in psychology.
7.4 How do you use models to analyze data?
In the prior parts of this chapter, we’ve described a suite of regression-based techniques – standard OLS, the generalized linear model, and linear mixed effects models – that can be used to model the data resulting from randomized experiments (as well as many other kinds of data). The advantage of regression models over the simpler estimation and inference methods we described in the prior two chapters is that these models can more effectively take into account a range of different kinds of variation including covariates, multiple manipulations, and clustered structure. Further, when used appropriately to analyze a well-designed randomized experiment, regression models can give an unbiased estimate of a causal effect of interest, our main goal in doing experiments.
But – practically speaking – how should go you about building a model for your experiment? What covariates should you include and what should you leave out? There are many ways to use models to explore datasets, but in this section we will try to sketch a default approach for the use of models to estimate causal effects in experiments in the most straightforward way. Think of this as a starting point. We’ll begin this section by giving a set of rules of thumb, then discuss a worked example. Our final subsections will deal with the issues of when you should include covariates in your model and how to check if your result is robust across multiple different model specifications.
7.4.1 Modeling rules of thumb
Our approach to statistical modeling is to start with a “default model” that is known in the literature as a saturated model. The saturated model of an experiment includes the full design of the experiment – all main effects and interactions – and nothing else. If you are manipulating a variable, include it in your model. If you are manipulating two, include them both and their interaction. If your design includes repeated measurements for participants, include a random effect of participant; if it includes experimental items for which repeated measurements are made, include random effect of stimulus.25
25 As discussed above, you can also include the “maximal” random effect structure (Barr et al. 2013), which involves random slopes as well as intercepts – but recognize that you cannot always fit such models.
Don’t include lots of other stuff in your default model. You are doing a randomized experiment, and the strength of randomized experiments is that you don’t have to worry about confounding based on the population (see Chapter 1). So don’t put a lot of covariates in your default model – usually don’t put in any!26
26 One corollary to having this kind of default perspective on data analysis: When you see an analysis that deviates substantially from the default, these deviations should provoke some questions. If someone drops a manipulation from their analysis, adds a covariate or two, or fails to control for some clustering in the data, did they deviate because of different norms in their sub-field, or was there some other rationale? This line of reasoning sometimes leads to questions about the extent to which particular analytic decisions are post-hoc and driven by the data (in other words, \(p\)-hacked). For an example, see the case study in Chapter 11.
This default saturated model then represents a simple summary of your experimental results. Its coefficients can be interpreted as estimates of the effects of interest, and it can be used as the basis for inferences about the relation of the experimental effect to the population using either frequentist or Bayesian tools.
Here’s a bit more guidance about this modeling strategy.
Preregister your model. If you change your analysis approach after you see your data, you risk \(p\)-hacking – choosing an analysis that biases the estimate of your effect of interest. As we discussed in Chapter 3 and as we will discuss in more detail in Chapter 11, one important strategy for minimizing this problem is to preregister your analysis.27
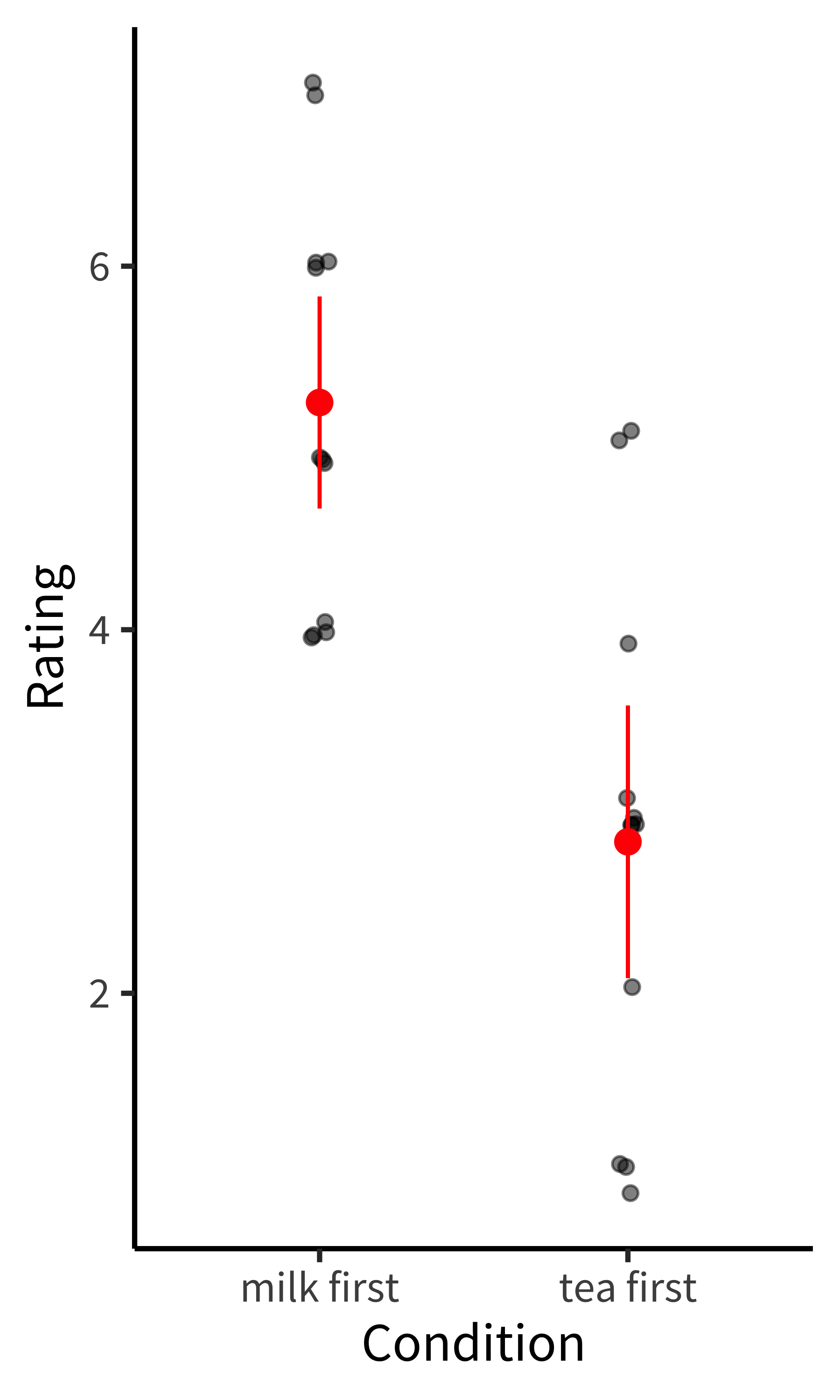
Visualize the model predictions against the observed data. As we’ll discuss in Chapter 15, the “default model” for an experiment should go alongside a “default visualization” known as the design plot that similarly reflects the full design structure of the experiment and any primary clusters. In visualizing data like those from our tea-tasting experiment, show individual participants’ average ratings (as in Figure 7.3). One way to check whether a model fits your data is then to plot it on top of those data. Sometimes this combination of model and data can be as simple as a scatter plot with a regression line. But seeing the model plotted alongside the data can often reveal a mismatch between the two. A model that does not describe the data very well is not a good source of generalizable inferences!
27 A side benefit of preregistration is it makes you think through whether your experimental design is appropriate – that is, is there actually an analysis capable of estimating the effect you want from the data you intend to collect?
- Interpret the model predictions. Once you have a model, don’t just read off the \(p\)-values for your coefficients of interest. Walk through the each coefficient, considering how it relates to your outcome variable. For a simple two group design like we’ve been considering, the condition coefficient is the estimate of the causal effect that you intended to measure! Consider its sign, its magnitude, and its precision (standard error or confidence interval).
That said, there are some contexts in which it does make sense to depart from the default saturated model. For example, there may be insufficient statistical power to estimate multiple interaction terms, or covariates might be included in the model to help handle certain forms of missing data. The default model simply represents a very good starting point.
7.4.2 A worked example

All this advice may seem abstract, so let’s put it into practice on a simple example. For a change, let’s look at an experiment that’s not about tea tasting. Here we’ll consider data from an experiment testing preschool children’s language comprehension (Stiller, Goodman, and Frank 2015). In this experiment, 2–5 year old children saw displays like the one in Figure 7.4. In the experimental condition, a puppet might say, for example, “My friend has glasses! Which one is my friend?” The goal was to measure how many children made the “pragmatic inference” that the puppet’s friend was the face with glasses and no hat.
To estimate the effect, participants were randomly assigned to either the experimental condition or to a control condition in which the puppet had eaten too much peanut butter and couldn’t talk, but they still had to guess which face was his friend. There were also three other types of experimental stimuli (houses, beds, and plates of pasta). Data from this experiment consisted of 588 total observations from 147 children, with all four stimuli presented to each child. The primary hypothesis of this experiment was that that preschool children could make pragmatic inferences by correctly inferring which of the three faces (for example) the puppet was describing.
code
If you want to follow along with this example, you’ll have to load the example data and do a little bit of preprocessing (also covered in Appendix D):
sgf <- read_csv("https://raw.githubusercontent.com/langcog/experimentology/main/data/tidyverse/stiller_scales_data.csv") |>
mutate(age_group = cut(age, 2:5, include.lowest = TRUE),
condition = factor(ifelse(condition == "Label", "Experimental", "Control")))All this advice may seem abstract, so let’s put it into practice on a simple example. For a change, let’s look at an experiment that’s not about tea tasting. Here we’ll consider data from an experiment testing preschool children’s language comprehension , we also use these data in D. In this experiment, 2–5 year old children saw displays like the one in Figure 7.4. In the experimental condition, a puppet might say, for example, “My friend has glasses! Which one is my friend?” The goal was to measure how many children made the “pragmatic inference” that the puppet’s friend was the face with glasses and no hat.
To estimate the effect, participants were randomly assigned to either the experimental condition or to a control condition in which the puppet had eaten too much peanut butter and couldn’t talk, but they still had to guess which face was his friend. There were also three other types of experimental stimuli (houses, beds, and plates of pasta). Data from this experiment consisted of 588 total observations from 147 children, with all four stimuli presented to each child. The primary hypothesis of this experiment was that that preschool children could make pragmatic inferences by correctly inferring which of the three faces (for example) the puppet was describing.
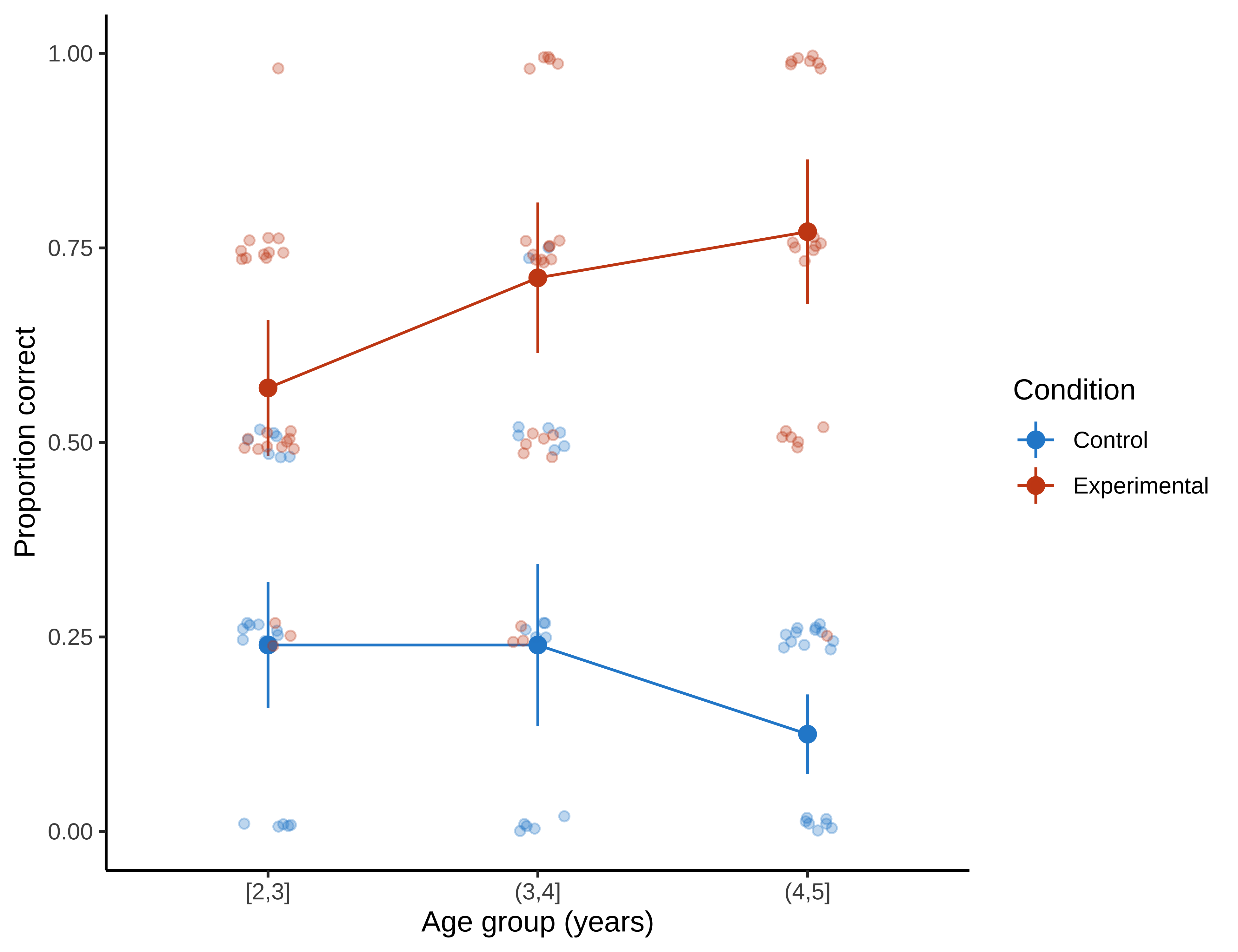
This experimental design looks a lot like some versions of our tea-tasting experiment. We have one primary condition manipulation (the puppet provides information versus does not), presented between-participants so that some participants are in the experimental condition and others are in the control condition. Our measurements are repeated within participants across different experimental stimuli. Finally, we have one important, pre-planned covariate: children’s age. Experimental data are plotted in Figure 7.5.28
28 Our sampling plan for this experiment was actually stratified across age, meaning that we intentionally recruited the same number of participants for each one-year age group – because we anticipated that age was highly correlated with children’s ability to succeed in this task. We’ll describe this kind of sampling in more detail in Chapter 10.
How should we go about making our default model for this dataset?29 We simply include each of these design factors in a mixed effects model; we use a logistic link function for our mixed effects model (a generalized linear mixed effects model) because we would like to predict correct performance on each trial, which is a binary variable. So that gives us an effect of condition and age as a covariate. We further add an interaction between condition and age in case the condition effect varies meaningfully across groups. Finally, we add random effects of participant, \(\gamma_i\), and experimental item, \(\gamma_t\).30
29 This experiment was not preregistered, but the paper includes a separate replication dataset with the same analysis.
30 As discussed above, this is a tricky decision-point; we could very reasonably have added random slopes as well.
The resulting model looks like this:
\[ \text{logit}( E[Y_{it}] ) = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \beta_3 X_{i1} X_{i2} + \gamma_i + \delta_t \]
Let’s break this complex equation down left to right:
- \(\text{logit}( E[Y_{it}] )\) says that we are predicting a logistic function of \(E[Y_{it}]\) (where \(Y_{it}\) indicates whether child \(i\) was correct on trial \(t\)).
- \(\beta_0\) is the intercept, our estimate of the average log-odds (i.e., the log of the odds ratio) of correct responses for participants in the control condition.
- \(\beta_1 X_{i1}\) is the condition predictor. \(\beta_1\) represents the change in log-odds associated with being in the experimental condition (the causal effect of interest!), and \(X_{i1}\) is an indicator variable that is 1 if child \(i\) is in the experimental condition and 0 for the control condition. Multiplying \(\beta_1\) by this indicator means that the predictor has the value 0 for participants in the control condition and \(\beta_1\) for those in the experimental condition.
- \(\beta_2 X_{i2}\) is the age predictor. \(\beta_2\) represents the difference in log-odds associated with one additional year of age for participants int he control condition[The age coefficient is a simple effect, meaning it is the effect of age in the control condition only. That’s because we have dummy coded the condition predictor. If we wanted the average age effect (the main effect) then we would need to use contrast coding, per the note in the Interactions section above.], and \(X_{i2}\) is the age for each participant.31
- \(\beta_3 X_{i1} * X_{i2}\) is the interaction between experimental condition and age. \(\beta_3\) represents the difference in log odds (i.e., the log of the odds ratio) that is associated with being one year older and in the experimental condition versus the control condition. This term is multiplied by both each child’s age and the condition indicator \(X_i\).
- \(\gamma_i\) is the random intercept for participant \(i\), capturing individual variation in the odds of success across trials.
- \(\gamma_t\) is the random intercept for stimulus \(t\), capturing variation in the odds of success across the four different stimuli.
31 We have centered our age predictor in this example so that all estimates from our model are for the average age of our participants. Centering is a good practice for modeling continuous predictors because it increases the interpretability of other parts of the model. For example, because age is centered in this model, the intercept \(\beta_0\) can be interpreted as the predicted odds of a correct trial for a participant in the control condition at the average age.
| term | estimate | conf.int | statistic | p.value |
|---|---|---|---|---|
| Control condition | -1.46 | [-1.88, -1.04] | -6.76 | < .001 |
| Age (years) | -0.38 | [-0.75, -0.01] | -1.99 | .046 |
| Expt condition | 2.26 | [1.82, 2.70] | 10.07 | < .001 |
| Age (years) * Expt condition | 0.92 | [0.42, 1.43] | 3.60 | < .001 |
code
To fit the model described above, the first step is to prepare your predictors. In this case, we center the age predictor.
sgf$age_centered <- scale(sgf$age, scale=FALSE)Again we use the lme4 package, this time with the glmer function. Again we have to specify our link function, just like in a standard GLM, by choosing the distribution family.
mod <- lme4::glmer(correct ~ age_centered * condition + (1|subid) + (1|item),
family = "binomial",
data = sgf)You can see a summary of the fitted model using summary(mod) as before. The only big difference from lm is that here you can extract both fixed and random effects (with fixef(mod) and ranef(mod) respectively).
Let’s estimate this model and see how it looks. We’ll focus here on interpretation of the so-called fixed effects (the main predictors), as opposed to the participant and item random effects.32 Table 7.2 shows the coefficients. Again, let’s walk through each.
32 Participant means are estimated to have a standard deviation of 0.23 (in log-odds) while items have a standard deviation of 0.27. These indicate that both of our random effects capture meaningful variation.
The intercept (control condition estimate) is \(\hat{\beta} = -1.46\), 95% CI \([-1.88, -1.04]\), \(z = -6.76\), \(p < .001\). This estimate reflects that the log-odds of a correct response for an average-age participant in the control condition is -1.46, which corresponds to a probability of 0.19. If we look at Figure 7.5), that estimate makes sense: 0.19 seems close to the average for the control condition.
The age effect estimate is \(\hat{\beta} = -0.38\), 95% CI \([-0.75, -0.01]\), \(z = -1.99\), \(p = .046\). This means there is a slight decrease in the log-odds of a correct response for older children in the control condition. Again, looking at Figure 7.5, this estimate is interpretable: we see a small decline in the probability of a correct response for the oldest age group.
The key experimental condition estimate then is \(\hat{\beta} = 2.26\), 95% CI \([1.82, 2.70]\), \(z = 10.07\), \(p < .001\). This estimate means that the log-odds of a correct response for an average-age participant in the experimental condition is the sum of the estimates for the control (intercept) and the experimental conditions: -1.46 + 2.26, which corresponds to a probability of 0.69. Grounding our interpretation in Figure 7.5, this estimate corresponds to the average value for the experimental condition.
Finally, the interaction of age and condition is \(\hat{\beta} = 0.92\), 95% CI \([0.42, 1.43]\), \(z = 3.60\), \(p < .001\). This positive coefficient reflects that with every year of age, the difference between control and experimental conditions grows.
In sum, this model suggests that there was a substantial difference in performance between experimental and control conditions, in turn supporting the hypothesis that children in the sampled age group can perform pragmatic inferences above chance.
This example illustrates the “default saturated model” framework that we recommend – the idea that a single regression model corresponding to the design of the experiment can yield an interpretable estimate of the causal effect of interest, even in the presence of other sources of variation.
depth
When does it makes sense to include covariates in a model?
Let’s come back to one piece of advice that we gave above about making a “default” model of an experiment: not including covariates. This advice can seem surprising. Many demographic factors are of interest to psychologists and other behavioral scientists, and in observational studies these factors will almost always be related to important life outcomes. So why not put them into our experimental models? After all, we did include age in our worked example above!
Well, if you have one or at most a small handful of covariates that you believe are meaningfully related to the outcome, you can plan in advance to put them in your model. If you think that your effect is likely to be moderated a specific demographic characteristic – as we did with age in our developmental example above – then this inclusion can be quite useful.
Further, including covariates can increase the precision of your estimates by reducing “noise” in your outcome, if you hypothesize that they interact. What’s surprising though is how little this adjustment does to increase your overall precision unless the correlation between covariate and outcome is very strong.
Figure 7.6 shows the relationship between estimation error and the inclusion of covariates via a simple simulation. Only when the correlation between covariate and outcome (e.g., age and tea rating is greater than \(r=0.6\) to \(r=0.8\) does this adjustment really help.
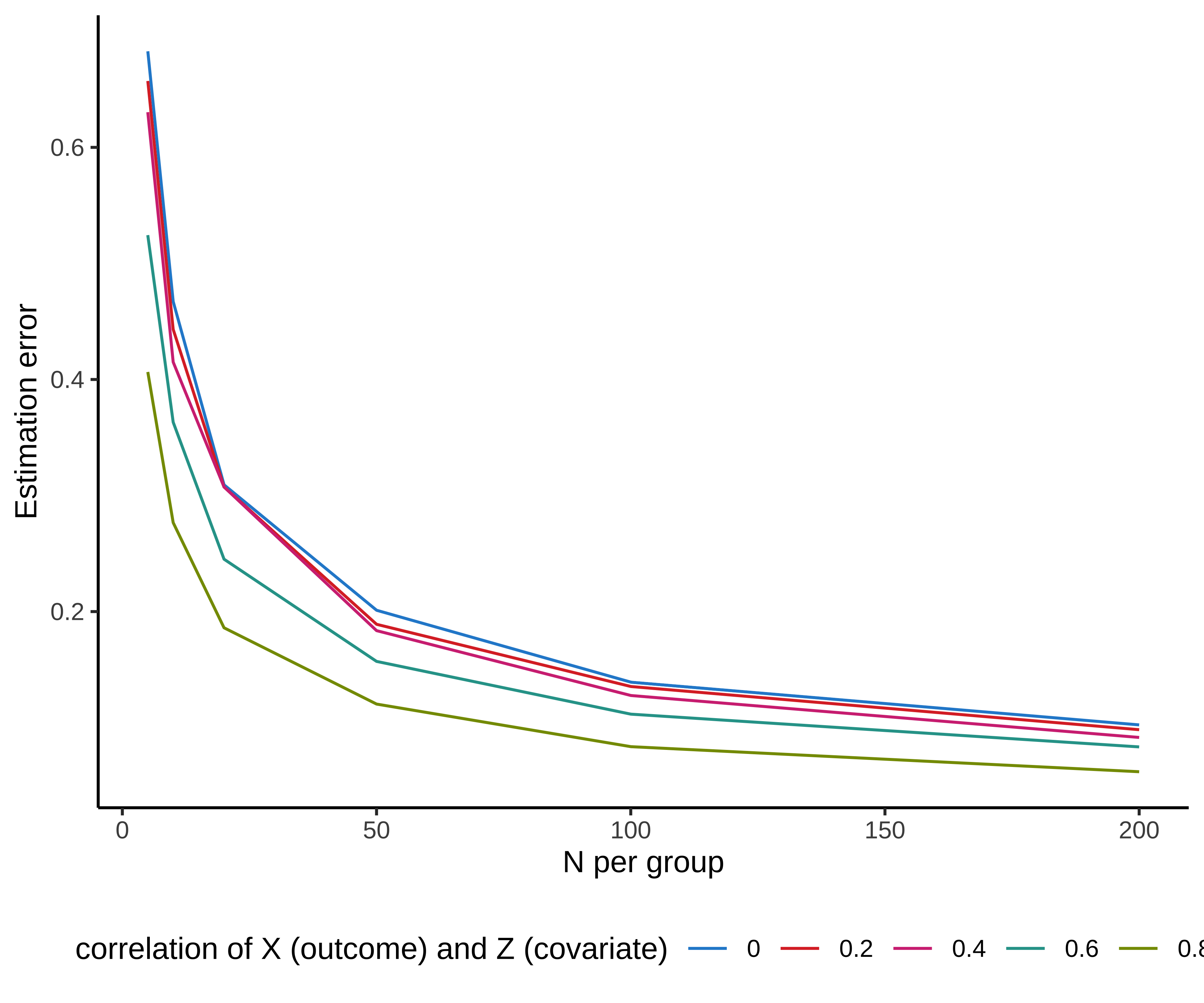
That said, there are quite a few reasons not to include covariates – motivating our recommendation to skip them in your default model unless you have very strong theory-based expectations for either (A) a correlation with the outcome or (B) a strong moderation relationship.
The first is simply because we don’t need to. Because randomization cuts causal links, our experimental estimate is an unbiased estimate of the causal effect of interest (at least for large samples). We are guaranteed that, in the limit of many different experiments, even though people with different ages will be in the different tea tasting conditions, this source of variation will be averaged out. Actually, including unnecessary covariates into models (slightly) decreases the probability that the model can detect a true effect (that is, it decreases statistical precision and power). Just by chance covariates can “soak up” variation in the outcome, leaving less to be accounted for by the true effect!
The second reason is that you can actually compromise your causal inference by including some covariates, particularly those that are collected after randomization. The logic of randomization is that you cut all causal links between features of the sample and the condition manipulation. But you can “uncut” these links by accident by adding variables into your model that are related to group status. This problem is generically called conditioning on post-treatment variables and a full discussion of is out of the scope of this book, but it’s something to avoid (and read up on if you’re worried about it; Montgomery, Nyhan, and Torres (2018)).
Finally, one of the standard justifications for adding covariates – because your groups are unbalanced – is actually ill-founded as well. People often talk about “unhappy randomization”: you randomize to the different tea-tasting groups, for example, but then it turns out the mean age is a bit different between groups. Then you do a t-test or some other statistical test and find out that you actually have a significant age difference. This practice makes no sense! Because you randomized, you know that the difference in ages occurred by chance. Further, incidental demographic differences between groups are unlikely to be important unless that characteristic is highly correlated with the outcome (see above). Instead, if the sample size is small enough that meaningfully large incidental differences could arise in important confounders, then it is preferable to stratify randomization on that confounder at the outset (and then also to include that covariate in modeling).
So these are our options: if a covariate is known to be very strongly related to our outcome, we can include it in our default model. Otherwise, we avoid a lot of trouble by leaving covariates out.
7.4.3 Robustness checks and the multiverse
Using the NHST statistical testing approach that has been common in the psychology literature, even a simple two factor experimental design affords a host of different \(t\)-tests and ANOVAs,33 offering many opportunities for \(p\)-hacking and selective reporting. We’ve been advocating here instead for a “default model” approach in which you pre-plan and pre-register a single regression model that captures the planned features of your experimental design including manipulations and sources of clustering. This approach can help you to navigate some of the complexity of data analysis by having a standard approach that you take in almost every case.
33 Although we don’t cover this point here, ANOVAs are also a special case of regression.
Not every dataset will be amenable to this approach, however. For complex experimental designs or unusual measures, sometimes it can be hard to figure out how to specify or fit the default saturated model. And especially in these cases, the choice of model can make a big difference to the magnitude of the reported effect. To quantify variability in effect size due to model choice, “Many Analysts” projects have asked a set of teams to approach a dataset using different analysis methods. The consistent result from these projects has been that there is substantial variability in outcomes depending on what approach is taken (Silberzahn et al. 2018; Botvinik-Nezer et al. 2020).
Robustness analysis (also sometimes called “sensitivity analysis” or “multiverse analysis”, which sounds cooler) is a technique for addressing the possibility that an individual analysis over- or under-estimates a particular effect by chance (Steegen et al. 2016). The general idea is that analysts explore a space of different possible analyses. In its simplest form, alternative model specifications can be reported in a supplement; more sophisticated versions of the idea call for averaging estimates across a range of possible specifications and reporting this average as the primary effect estimate.
The details of this kind of analysis will vary depending on what you are worried about your model being sensitive to. One analyst might be concerned about the effects of adding different covariates; another might be using a Bayesian framework and be concerned about sensitivity to particular prior values. If you get similar results across many different specifications, you can sleep better at night. The primary principle to take home is a bit of humility about our models. Any given model is likely wrong in some of its details. Investigating the sensitivity of your estimates to the details of your model specification is a good idea.
7.5 Chapter summary: Models
In the last three chapters, we have spelled out a framework for data analysis that focuses on our key experimental goal: a measurement of a particular causal effect. We began with basic techniques for estimating effects and making inferences about how these effects estimated from a sample can be generalized to a population. This chapter showed how these ideas naturally give rise to the idea of making models of data, which allow estimation of effects in more complex designs. Simple regression models, which are formally identical to other inference methods in the most basic case, can be extended with the generalized linear model as well as with mixed effects models. Finally, we ended with some guidance on how to build a “default model” – an (often pre-registered) regression model that maps onto your experimental design and provides the primary estimate of your key causal effect.
discussion questions
Choose a paper that you have read for your research and take a look at the statistical analysis. Does the reporting focus more on hypothesis testing or on estimating effect sizes?
We focused here on the linear model as a tool for building models, contrasting this perspective with the common “statistical testing” mindset. But – here’s the mind-blowing thing – most of those statistical tests are special cases of the linear model anyway. Take a look at this extended meditation on the equivalences between tests and models: https://lindeloev.github.io/tests-as-linear/#9_teaching_materials_and_a_course_outline. If the paper you chose for question 1 used tests, could their tests be easily translated to models? How would the use of a model-based perspective change the results section of the paper?
Take a look at this cool visualization of hierarchical (mixed effect) models: http://mfviz.com/hierarchical-models/. In your own research, what are the most common units that group together your observations?
readings
An opinionated practical guide to regression modeling and data description: Gelman, A., Hill, J., & Vehtari, A. (2020). Regression and other stories. Cambridge University Press. Free online at https://avehtari.github.io/ROS-Examples/.
A more in-depth introduction to the process of developing Bayesian models of data that allow for estimation and inference in complex datasets: McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan. Chapman and Hall/CRC. Free materials available at https://xcelab.net/rm/statistical-rethinking/.
References
Barr, Dale J, Roger Levy, Christoph Scheepers, and Harry J Tily. 2013. “Random Effects Structure for Confirmatory Hypothesis Testing: Keep It Maximal.” Journal of Memory and Language 68 (3): 255–78.
Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2014. “Fitting Linear Mixed-Effects Models Using Lme4.” arXiv Preprint arXiv:1406.5823.
Bie, Ruofan, Sebastien Haneuse, Nathan Huey, Jonathan Schildcrout, and Glen McGee. 2021. “Fitting Marginal Models in Small Samples: A Simulation Study of Marginalized Multilevel Models and Generalized Estimating Equations.” Statistics in Medicine 40 (24): 5298–5312.
Botvinik-Nezer, Rotem, Felix Holzmeister, Colin F Camerer, Anna Dreber, Juergen Huber, Magnus Johannesson, Michael Kirchler, et al. 2020. “Variability in the Analysis of a Single Neuroimaging Dataset by Many Teams.” Nature 582 (7810): 84–88.
Davis, Matthew J. 2010. “Contrast Coding in Multiple Regression Analysis: Strengths, Weaknesses, and Utility of Popular Coding Structures.” Journal of Data Science 8 (1): 61–73.
Galton, Francis. 1877. “Typical Laws of Heredity.” In. Royal Institution of Great Britain.
Mancl, Lloyd A, and Timothy A DeRouen. 2001. “A Covariance Estimator for GEE with Improved Small-Sample Properties.” Biometrics 57 (1): 126–34.
McElreath, Richard. 2018. Statistical Rethinking: A Bayesian Course with Examples in r and Stan. Chapman; Hall/CRC.
Montgomery, Jacob M, Brendan Nyhan, and Michelle Torres. 2018. “How Conditioning on Posttreatment Variables Can Ruin Your Experiment and What to Do about It.” Am. J. Pol. Sci. 62 (3): 760–75.
Silberzahn, Raphael, Eric L Uhlmann, Daniel P Martin, Pasquale Anselmi, Frederik Aust, Eli Awtrey, Štěpán Bahnı́k, et al. 2018. “Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results.” Advances in Methods and Practices in Psychological Science 1 (3): 337–56.
Steegen, Sara, Francis Tuerlinckx, Andrew Gelman, and Wolf Vanpaemel. 2016. “Increasing Transparency Through a Multiverse Analysis.” Perspectives on Psychological Science 11 (5): 702–12. https://doi.org/10.1177/1745691616658637.
Stiller, Alex J, Noah D Goodman, and Michael C Frank. 2015. “Ad-Hoc Implicature in Preschool Children.” Language Learning and Development 11 (2): 176–90.