2 Theories
learning goals
- Define theories and their components
- Contrast different philosophical views on scientific theories
- Analyze features of an experiment that can lead to strong tests of theory
- Discuss the role of formalization in theory development
When you do an experiment, sometimes you just want to see what happens, like a kid knocking down a tower made of blocks. And sometimes you want to know the answer to a specific applied question, like “will giving a midterm vs. weekly quizzes lead students in a class to perform better on the final?” But more often, our goal is to create theories that help us explain and predict new observations.
What is a theory? We’ll argue here that we should think of psychological theories as sets of proposed relationships among constructs, which are variables that we think play causal roles in determining behavior. In this conception of theories, the role of causality is central: theories are guesses about the causal structure of the mind and about the causal relationships between the mind and the world. This definition doesn’t include everything that gets called a “theory” in psychology. We describe the continuum between theories and frameworks – broad sets of ideas that guide research but don’t make specific contact with particular empirical observations.
We begin this chapter by talking about the specific enterprise of constructing psychological theories. We’ll then discuss how theories make contact with data, reviewing a bit of the philosophy of science, and give some guidance on how to construct experiments that test theories. We end by discussing the relationship between theories and quantitative models.
2.1 What is a psychological theory?
The definition we just gave for a psychological theory is that it is a proposed set of causal relationships among constructs that helps us explain behavior. Let’s look at the ingredients of a theory: the constructs and the relationships between them. Then we can ask about how this definition relates to other things that get called “theories” in psychology.
2.1.1 Psychological constructs
Constructs are the psychological variables that we want our theory to describe, like “money” and “happiness” in the example from last chapter. At first glance, it might seem odd that we need a specific name for these variables. But in probing the relationship between money and happiness, we will have to figure out a way to measure happiness. Let’s say we just ask people to answer the question “how happy are you?” by giving ratings on a 1 (miserable) to 10 (elated) scale.
Now say someone in the study reports they are an 8 on this scale. Is this really how happy they are? What if they weren’t concentrating very hard on the rating, or if they thought the researcher wanted them to be happy? What if they act much less happy in their interactions with family and friends?
We resolve this dilemma by saying that the self-report ratings we collect are only a measure of a latent construct, happiness. The construct is latent because we can never see it directly, but we think it has a causal influence on the measure: happier people should, on average, provide higher ratings. But many other factors can lead to noise or bias in the measurement, so we shouldn’t mistake those ratings as actually being the construct.
The particular question “how happy are you?” is one way of going from the general construct to a specific measure. The general process of going from construct to a specific instantiation that can be measured or manipulated is called operationalization. Happiness can be operationalized by self-report, but it can also be operationalized many other ways, for example through a measure like the use of positive language in a personal essay, or by ratings by friends, family, or a clinician. These decisions about how to operationalize a construct with a particular measure are tricky and consequential, and we discuss them extensively in Chapter 8. Each different operationalization might be appropriate for a specific study, yet it would require some justification and argument to connect each one to the others.
Proposing a particular construct is a very important part of making a theory. For example, a researcher might worry that self-reported happiness is very different than someone’s well-being as observed by the people around them, and assert that happiness is not a single construct but rather a group of distinct constructs. This researcher would then be surprised to know that self-reports of happiness relate very highly to others’ perceptions of a person’s well-being (Sandvik, Diener, and Seidlitz 1993).1
1 Sometimes positing the construct is the key part of a theory. g (general intelligence) is the classic psychological example of a single-construct theory. The idea behind g theory is that the best measure of general intelligence is the shared variance between a wide variety of different tests. The decision to theorize about and measure a single unified construct for intelligence – rather than say, many different separate kinds of intelligence – is itself a controversial move.
Even external, apparently non-psychological variables like money don’t have direct effects on people, but rather operate through psychological constructs. People studying money seriously as a part of psychological theories think about perceptions of money in different ways depending on the context. For example, researchers have written about the importance of how much money you have on hand based on when in the month your paycheck arrives (Ellwood-Lowe, Foushee, and Srinivasan 2022), but have also considered perceptions of long-term accumulation of wealth as a way of conceptualizing people’s understanding of the different resources available to White and Black families (Kraus et al. 2019).
Finally, a construct can be operationalized through a manipulation: in our money-happiness example, we operationalized “more money” in our theory with a gift of a specific amount of cash. We hope you see through these examples that operationalization is a huge part of the craft of being a psychology researcher – taking a set of abstract constructs that you’re interested in and turning them into a specific experiment with a manipulation and a measure that tests your causal theory. We’ll have a lot more to say about how this is done in Chapter 9.
2.1.2 The relationships between constructs
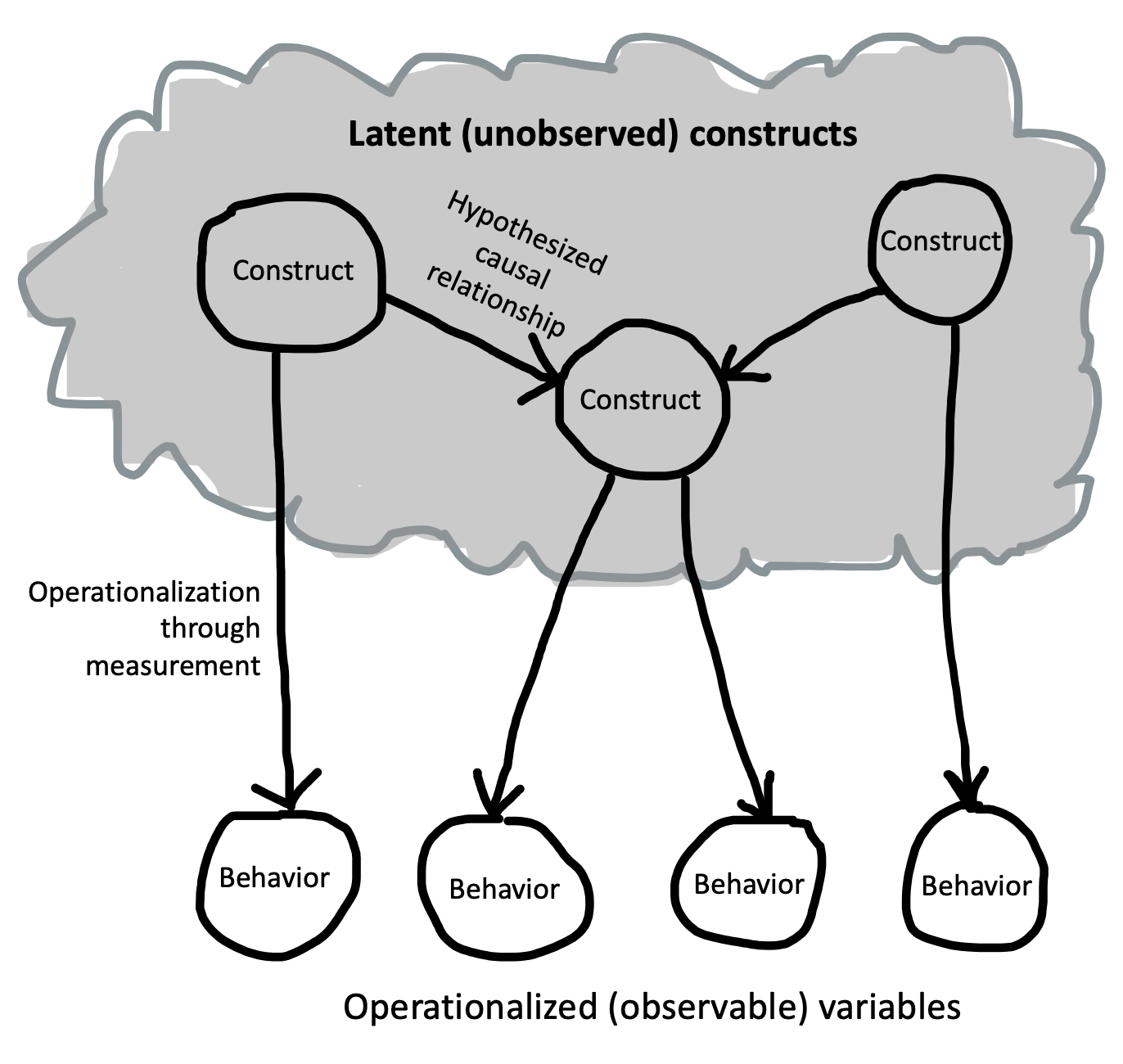
Constructs gain their meaning in part via their own definitions and operationalizations, but also in part through their causal relationships to other constructs. Figure 2.1 shows a schematic of what this kind of theory might look like – as you can see, it looks a lot like the DAGs that we introduced in the last chapter! That’s no accident. The arrows here also describe hypothesized causal links.2
2 Sometimes these kind of diagrams are used in the context of a statistical method called Structural Equation Modeling, where circles represent constructs and lines represent their relationships with one another. Confusingly, structural equation models are also used by many researchers to describe psychological theories. The important point for now is that they are one particular statistical formalism, not a general tool for theory building – the points we are trying to make here are more general.
This web of constructs and assumptions is what Cronbach and Meehl (1955) referred to as a “nomological network” – a set of proposals about how different entities are connected to one another. The tricky part is that the key constructs are never observed directly. They are in people’s heads.3 So researchers only get to probe them by measuring them through specific operationalizations.
3 We’re not saying these should correspond to specific brain structures. They could, but most likely they won’t. The idea that psychological constructs are not the same as any particular brain state (and especially not any particular brain region) is called “multiple realizability” by philosophers, who mostly agree that psychological states can’t be reduced to brain states, as much as philosophers agree on anything (Block and Fodor 1972 et seq.).
One poetic way of thinking about this idea is that the theoretical system of constructs “floats… above the plane of observation and is anchored to it by the rules of [measurement].” (Hempel 1952). So, even if your theory posits that two constructs (say, money and happiness) are directly related, the best you can do is manipulate one operationalization and measure another operationalization. If this manipulation doesn’t produce any effect, it’s possible that you are wrong and money does not cause happiness – but it is also possible that your operationalizations are poor.
Here’s a slightly different way of thinking about a theory. A theory provides a compression of potentially complex data into much a smaller set of general factors. If you have a long sequence of numbers, say [2 4 8 16 32 64 128 256 …], then the expression \(2^n\) serves as a compression of this sequence – it’s a short expression that tells you what numbers are in vs. out of the sequence. In the same way, a theory can compress a large set of observations (maybe data from many experiments) into a small set of relationships between constructs. Now, if your data are noisy, say [2.2 3.9 8.1 16.1 31.7 … ], then the theory will not be a perfect representation of the data. But it will still be useful.
In particular, having a theory allows you to explain observed data and predict new data. Both of these are good things for a theory to do. For example, if it turned out that the money causes happiness theory was true, we could use it to explain observations such as greater levels of happiness among wealthy people. We could also make predictions about the effects of policies like giving out a universal basic income on overall happiness.4
4 The relationship between money and happiness is actually much more complicated than what we’re assuming here. For example, Killingsworth, Kahneman, and Mellers (2023) describes a collaboration between two sets of researchers that had different viewpoints on the connection between money and happiness.
Explanation is an important feature of good theories, but it’s also easy to trick yourself by using a vague theory to explain a finding post-hoc (after the fact). Thus, the best test of a theory is typically a new prediction, as we discuss below.
2.1.3 Specific theories vs. general frameworks
You may be thinking, “psychology is full of theories but they don’t look that much like the ones you’re talking about!” Very few of the theories that bear that label in psychology describe causal relationships linking clearly defined and operationalized constructs. You also don’t see that many DAGs, though these are getting (slightly) more common lately (Rohrer 2018).
Here’s an example of something that gets called a theory yet doesn’t share the components described above. Bronfenbrenner (1992)’s Ecological Systems Theory (EST) is pictured in Figure 2.2. The key thesis of this theory is that children’s development occurs in a set of nested contexts that each affect one another and in turn affect the child. This theory has been immensely influential. Yet if it’s read as a causal theory, it’s almost meaningless: nearly everything connects to everything in both directions and the constructs are not operationalized – it’s very hard to figure out what kind of predictions it makes!
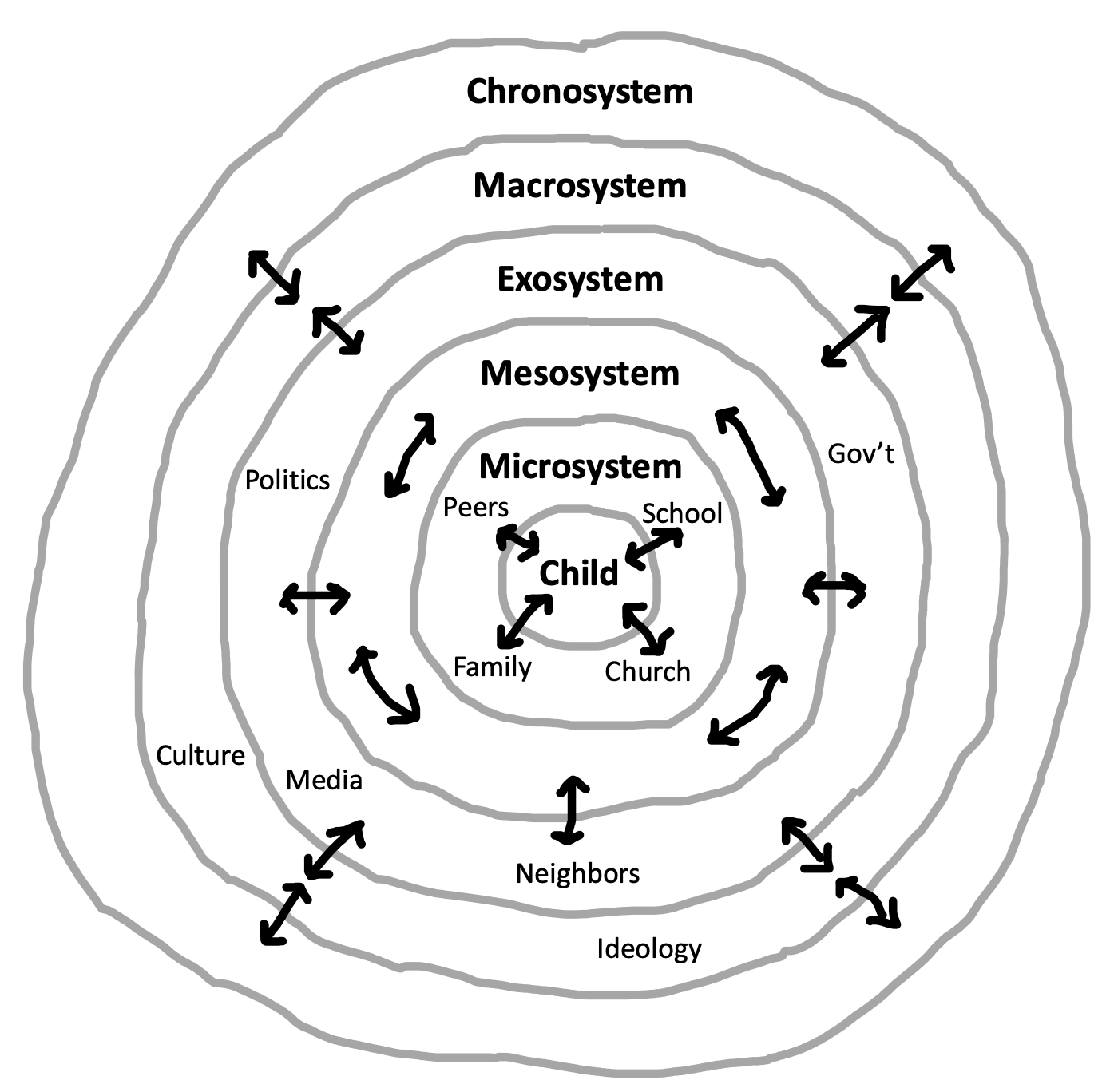
EST is not really a theory in the sense that we are advocating for in this chapter (and the same goes for many other very interesting ideas in psychology). It’s not a set of causal relationships between constructs that allow specific predictions about future observations. EST is instead a broad set of ideas about what sorts of theories are more likely to explain specific phenomena. For example, it helps remind us that a child’s behavior is likely to be influenced by a huge range of factors, such that any individual theory cannot just focus on an individual factor and hope to provide a full explanation. In this sense, EST is a framework: it guides and inspires specific theories – in the sense we’ve discussed here, namely a set of causal relationships between constructs – without being a theory itself.
Frameworks are often incredibly important. Ideas like EST have inspired huge amounts of interesting research. They can also make a big difference to practice. For example, EST supports a model in social work in which children’s needs are considered not only as the expression of specific internal developmental issues but also as stemming from a set of overlapping contextual factors (Ungar 2002). Concretely, a therapist might be more likely to examine family, peer, and school environments when analyzing a child’s situation through the lens of EST.
There’s a continuum between precisely specified theories and broad frameworks. Some theories propose interconnected constructs but don’t specify the relationships between them, or don’t specify how those constructs should be operationalized. So when you read a paper that says it proposes a “theory,” it’s a good idea to to ask whether it describes specific relations between operationalized constructs. If it doesn’t that, it may be more of a framework than a theory.
ethical considerations
Theory development isn’t just about knowledge for knowledge’s sake – it has implications for the technologies and policies built off the theories.
One case study comes from Edward Clarke’s infamous theory regarding the deleterious effects of education for women (Clarke 1884). Clarke posited that (1) cognitive and reproductive processes relied on the same fixed pool of energy, (2) relative to men, women’s reproductive processes required more energy, and that (3) expending too much energy on cognitive tasks like education depleted women of the energy needed to maintain a healthy reproductive system. Based on case studies, Clarke suggested that education was causing women to become ill, experience fertility issues, and birth weaker offspring. He thus concluded that “boys must study and work in a boy’s way, and girls in a girl’s way” (p. 18).
Clarke’s work is a chilling example of the implication of a poorly-developed theory. In this scenario, Clarke had neither instruments that allowed him to measure his constructs or experiments to measure the causal connections between them. Instead, he merely highlighted case studies that were consistent with his idea (while simultaneously dismissing cases that were inconsistent). His ideas eventually lost favor – especially as they were subjected to more rigorous tests. But Clarke’s arguments were used to attempt to dissuade women from pursuing higher education and hindered educational policy reform.
2.2 How do we test theories?
Our view of psychological theories is that they describe a set of relationships between different constructs. How can we test theories and decide which one is best? We’ll first describe falsificationism, a historical viewpoint on this issue that has been very influential in the past and that connects to ideas about statistical inference presented in Chapter 6. We’ll then turn to a more modern viewpoint, holism, that recognizes the interconnections between theory and measurement.
2.2.1 Falsificationism
One historical view that resonates with many scientists is the philosopher Karl Popper’s falsificationism. For Popper, a scientific theory is a set of hypotheses about the world that instantiate claims like the connection between money and happiness.5 What makes a statement a scientific hypothesis is that it can be disproved (i.e., it is falsifiable) by an observation that contradicts it. For example, observing a lottery winner who immediately becomes depressed would falsify the hypothesis that receiving money makes you happier.
5 Earlier we treated the claim that money caused happiness as a theory. It is one! It’s just a very simple theory that has only one hypothesized connection in it.
On Popper’s view, theories are never confirmed. The hypotheses that made up his theories were universal statements. You could never prove them right; you could only fail to find falsifying evidence. Seeing hundreds of people get happier when they received money would not prove that the money-happiness hypothesis was universally true. There could always be a counter-example around the corner.
Popper’s theory doesn’t really describe how scientists work. For example, scientists like to say that their evidence “supports” or “confirms” their theory, and Popper’s falsificationism rejects this kind of talk. A falsificationist says that confirmation is an illusion; that the theory is simply surviving to be tested another day. This strict falsificationist perspective is unpalatable to many scientists. After all, if we observe that hundreds of people get happier when they receive money, it seems like this should at least slightly increase our confidence that money causes happiness!6
6 An alternative perspective comes from the Bayesian tradition that we’ll learn more about in Chapters 5 and 6. In a nutshell, Bayesians propose that our subjective belief in a particular hypothesis can be captured by a probability, and that our scientific reasoning can then be described by a process of normative probabilistic reasoning (Strevens 2006). The Bayesian scientist distributes probability across a wide range of alternative hypotheses; observations that are more consistent with a hypothesis increase the hypothesis’s probability (Sprenger and Hartmann 2019).
2.2.2 A holistic viewpoint on theory testing
The key issue that leads us to reject strict falsificationism is the observation that no individual hypothesis (a part of a theory) can be falsified independently. Instead, a large series of what are called auxiliary assumptions (or auxilliary hypotheses) are usually necessary to link an observation to a theory (Lakatos 1976). For example, if giving some individual person money didn’t change their happiness, we wouldn’t immediately throw out our theory that money causes happiness. Instead, the fault might be in any one of our auxiliary assumptions, like our measurement of happiness, or our choice of how much money to give or when to give it. The idea that individual parts of a theory can’t be falsified independently is sometimes called holism.
One consequence of holism is that the relationship between data and theory isn’t always straightforward. An unexpected observation may not cause us to give up on a main hypothesis in our theory – but it will often cause us to question our auxiliary assumptions instead (e.g., how we operationalize our constructs). Thus, before abandoning our theory of money causing happiness, we might want to try several happiness questionnaires!
The broader idea of holism is supported by historical and sociological studies of how science progresses, especially in the work of Kuhn (1962). Examining historical evidence, Kuhn found that scientific revolutions didn’t seem to be caused by the falsification of a theoretical statement via an incontrovertible observation. Instead, Kuhn described scientists as mostly working within paradigms: sets of questions, assumptions, methods, phenomena, and explanatory hypotheses.
Paradigms allow for activities Kuhn described as normal science – that is, testing questions within the paradigm, explaining new observations or modifying theory to fit these paradigms. But normal science is punctuated by periods of crisis when scientists begin to question their theory and their methods. Crises don’t happen just because a single observation is inconsistent with the current theory. Rather, there will often be a holistic transition to a new paradigm, typically because of a striking explanatory or predictive success – often one that’s outside the scope of the current working theory entirely.
In sum, the lesson of holism is that we can’t just put our theories in direct contact with evidence and think that they will be supported or overturned. Instead, we need to think about the scope of our theory (in terms of the phenomena and measures it is meant explain), as well as the auxiliary hypotheses – operationalizations – that link it to specific observations.
2.3 Designing experiments to test theory
One way of looking at theories is that they let us make bets. If we bet on a spin of the roulette wheel in Figure 2.3 that it will show us red as opposed to black, we have almost a 50% chance of winning the bet. Winning such a bet is not impressive. But if we call a particular number, the bet is riskier because we have a much smaller chance of being right. Cases where a theory has many chances to be wrong are called risky tests (Meehl 1978).7
7 Even if you’re not a falsificationist like Popper, you can still think it’s useful to try and falsify theories! Although a single observation is not always enough to overturn a theory, it’s still a great research strategy to look for those observations that are most inconsistent with the theory.
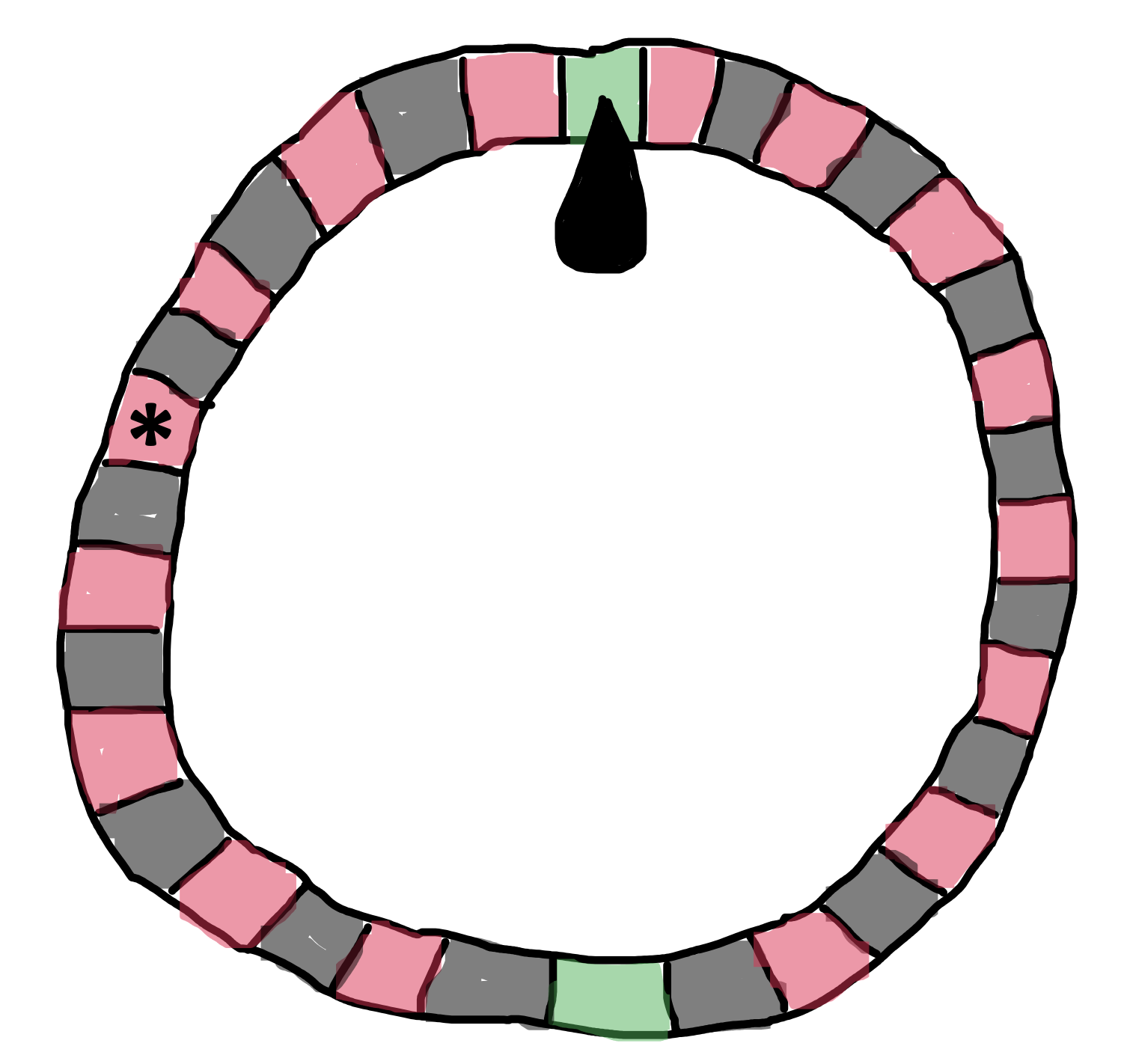
Much psychology consists of verbal theories. Verbal theories make only qualitative predictions, so it is hard convincingly show them to be wrong (Meehl 1990). In our discussion of money and happiness, we just expected happiness to go up as money increased. We would have accepted any increase in happiness (even if very small) as evidence confirming our hypothesis. Predicting that it does is a bit like betting on red with the roulette wheel – it’s not surprising or impressive when you win. And in psychology, verbal theories often predict that multiple factors interact with one another. With these theories, it’s easy to say that one or the other was “dominant” in a particular situation, meaning you can predict almost any direction of effect.
To test theories, we should design experiments to test conditions where our theories make “risky” predictions. A stronger version of the money-happiness theory might suggest that happiness increases linearly in the logarithm of income (Killingsworth, Kahneman, and Mellers 2023). This specific mathematical form for the relationship – as well as the more specific operationalization of money as income – creates opportunities for making much riskier bets about new experiments. This kind of case is more akin to betting on a specific number on the roulette wheel: when you win this bet, it is quite surprising!8
8 Theories are often developed iteratively. It’s common to start with a theory that is less precise and hence, that has fewer opportunities for risky tests. But by collecting data and testing different alternatives, it’s often possible to refine the theory so that it is more specific and allows riskier tests. As we discuss below, formalizing theories using mathematical or computational models is one important route to making more specific predictions and creating riskier tests.
Testing theoretical predictions also requires precise experimental measurements. As we start to measure the precision of our experimental estimates in Chapter 6, we’ll see that the more precise our estimate is, the more values are inconsistent with it. In this sense, a risky test of a theory requires both a very specific prediction and a precise measurement. (Imagine spinning the roulette wheel but seeing such a blurry image of the result that you can’t really tell where the ball is. Not very useful.)
Even when theories make precise predictions, they can still be too flexible to be tested. When a theory has many free parameters – numerical values that can be fit to a particular dataset, changing the theories predictions on a case-by-case basis – then it can often predict a wide range of possible results. This kind of flexibility reduces the value of any particular experimental test, because the theorist can always say after the fact that the parameters were wrong but not the theory itself (Roberts and Pashler 2000).
One important way to remove this kind of flexibility is to make predictions in advance, holding all parameters constant. A preregistration is a great way to do this – the experimenter derives predictions and specifies in advance how they will be compared to the results of the experiment. We’ll talk much more about the process of preregistration in Chapter 11.
Finally, we’ve been focusing mostly on testing a single theory. But the best state of affairs is if a theory can make a very specific prediction that other theories don’t make. If competing theories both predict that money increases happiness to the same extent, then data consistent with that predicted relationship don’t differentiate between the theories, no matter how specific the prediction might be. The experiment that teaches us the most is going to be the one where a very specific pattern of data is predicted according to one theory and another.9
9 We can use this idea, which comes from Bayesian statistics, to try to figure out what the right experiment is by considering which specific experimental conditions derive differences between theories. In fact, the idea of choosing experiments based on the predictions that different theories make has a long history in statistics (Lindley 1956); it’s now called optimal experiment design (Myung, Cavagnaro, and Pitt 2013; Ouyang et al. 2018). The idea is, if you have two or more theories spelled out mathematically or computationally, you can simulate their predictions across a lot of conditions and pick the most informative conditions to run as an actual experiment.
2.4 Formalizing theories
Say we have a set of constructs we want to theorize about. How do we describe our ideas about the relationships between them so that we can make precise predictions that can be compared with other theories? As one writer noted, mathematics is “unreasonably effective” as a vocabulary for the sciences (Wigner 1990). Indeed, there have been calls for greater formalization of theory in psychology for at least the last 50 years (Harris 1976).
depth
A universal law of generalization?
How do you take what you know and apply it to a new situation? One answer is that you use the same answer that has worked in similar situations. To do this kind of extrapolation, however, you need a notion of similarity. Early learning theorists tried to measure similarity by creating an association between a stimulus – say a projected circle of light of a particular size – and a reward by repeatedly presenting them together. After this association was learned, they would test generalization by showing circles of different sizes and measuring the strength of the expectation for a reward. These experiments yielded generalization curves: the more similar the stimulus, the more people and other animals would give the same response, signaling generalization.
Shepard (1987) was interested in unifying the results of these different experiments. The first step in this process was establishing a stimulus space. He used a procedure called “multidimensional scaling” to infer how close stimuli were to each other on the basis of how strong the generalization between them was. When he plotted the strength of the generalization by the distance between stimuli within this space (their similarity), he found an incredibly consistent pattern: generalization decreased exponentially as similarity decreased.
He argued that this described a “universal law” that governed the relationship between similarity and generalization for almost any stimulus, whether it was the size of circles, the color of patches of light, or the similarity between speech sounds. Later work has even extended this same framework to highly abstract dimensions such as the relationships between numbers of different types [e.g., being even, being powers of 2, etc.; Tenenbaum (2000)].
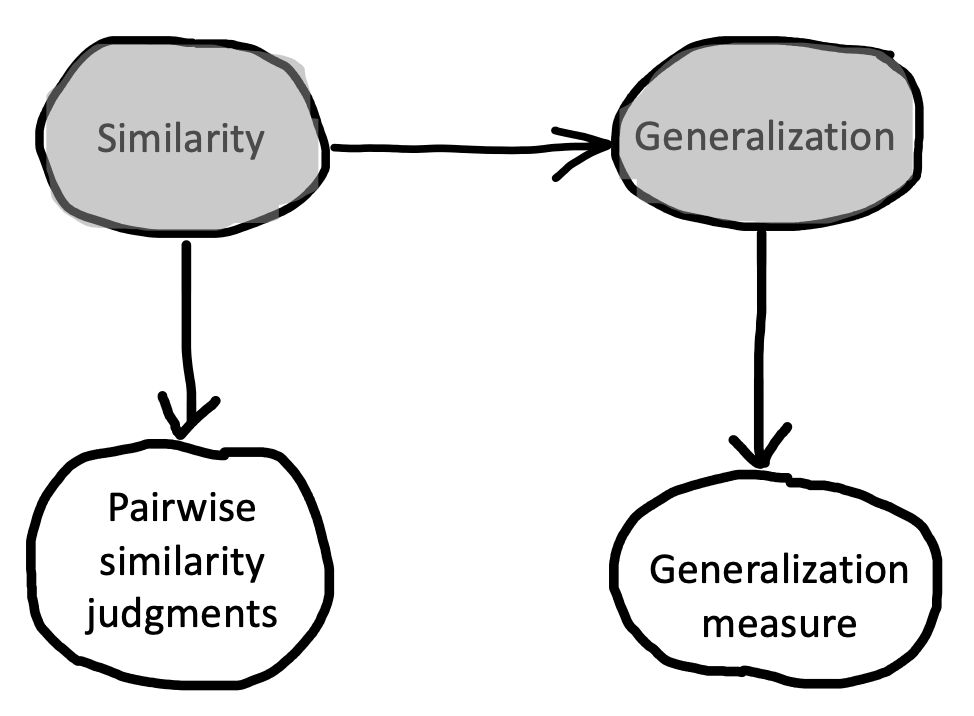
The pattern shown in Shepard’s work is an example of inductive theory building. In the vocabulary we’re developing, Shepard ran (or obtained the data from) randomized experiments in which the manipulation was stimulus dimension (e.g., circle size) and the measure was generalization strength. Then the theory that Shepard proposed was that manipulations of stimulus dimension acted to change the perceived similarity between the stimuli. His theory thus linked two constructs: stimulus similarity and generalization strength (Figure 2.4). Critically the causal relationship he described was not just a qualitative relationship but instead a specific mathematical form.
Shepard wrote in the conclusion of his 1987 paper, “Possibly, behind the diverse behaviors of humans and animals, as behind the various motions of planets and stars, we may discern the operation of universal laws.” While Shepard’s dream is an ambitious one, it defines an ideal for psychological theorizing.
There is no one approach that will be right for theorizing across all areas of psychology (Oberauer and Lewandowsky 2019; Smaldino 2020). Mathematical theories like Shepard (1987) (see Depth box) have long been one tool that allows for precise statements of particular relationships.
Computational or formal artifacts are not themselves psychological theories, but they can be used to create psychological theories via the mapping of constructs onto entities in the model and the use of the principles of the formalism to instantiate psychological hypotheses or assumptions (Guest and Martin 2021).10 Yet stating such clear and general laws feels out of reach in many cases. If we had more Shepard-style theorists or theories, perhaps we’d be in a better place. Or perhaps such “universal laws” are simply out of reach for most of human behavior.
10 This book won’t go into more details about routes to building computational theories, but if you are interested, we encourage you to explore these frameworks as a way to deepen your theoretical contributions and to sharpen your experimental choices.
An alternative approach creates statistical models of data that incorporate substantive assumptions about the structure of the data. We use such models all the time for data analysis. The trouble is, we often don’t interpret them as having substantive assumptions about the structure of the data, even when they do (Fried 2020)! But if we examine these assumptions explicitly, even the simplest statistical models can be productive tools for building theories.
For example, if we set up a simple linear regression model to estimate the relationship between money and happiness, we’d be positing a linear relationship between the two variables – that an increase in one would always lead to a proportional increase in the other.11 If we fit the model to a particular dataset, we could then look at the weights of the model. Our theory might then then be something like “giving people $100 causes .2 points of increase in happiness on a self-report scale.”
11 Linear models are ubiquitous in the social sciences because they are convenient to fit, but as theoretical models they are deeply impoverished. There is a lot you can do with a linear regression, but in the end, most interesting processes are not linear combinations of factors!
Obviously, this regression model is not a very good theory of the broader relationship between money and happiness, since it posits that everyone’s happiness would be at the maximum on the 10 point scale if you gave them (at most) $4500. It also doesn’t tell us how this theory would generalize to other people, other measures of happiness, or other aspects of the psychological representation of money such as income or wealth.
From our viewpoint, these sorts of questions are not distractions – they are the critical work of moving from experiment to theory (Smaldino 2020)! In Chapter 7, we try to draw out this idea further, reconstruing common statistical tests as models that can be repurposed to express contentful scientific hypotheses while recognizing the limitations of their assumptions.
One of the strengths of modern cognitive science is that it provides a very rich set of tools for expressing more complex statistical models and linking them to data. For example, the modern Bayesian cognitive modeling tradition grew out of work like Shepard’s; in these models, a system of equations defines a probability distribution that can be used to estimate parameters, predict new data, or make other inferences (Goodman, Tenenbaum, and Contributors 2016). And neural network models – which are now fueling innovations in artificial intelligence – have a long history of being used as substantive models of human psychology (Elman, Bates, and Johnson 1996).
In our discussion, we’ve presented theories as static entities that are presented, tested, confirmed, and falsified. That’s a simplification that doesn’t take into account the ways that theories – especially when instantiated as formal models – can be flexibly adjusted to accommodate new data (Navarro 2019). Most modern computational theories are more like a combination of core principles, auxiliary assumptions, and supporting empirical assumptions. The best theories are always being enlarged and refined in response to new data.12
12 In the thinking of the philosopher Imre Lakatos, a “productive” research program is one where the core principles are gradually supplemented with a limited set of additional assumptions to explain a growing base of observations. In contrast, a “degenerate” research program is one in which you are constantly making ad-hoc tweaks to the theory to explain each new datapoint (Lakatos 1976).
2.5 Chapter summary: Theories
In this chapter, we characterized psychological theories as a set of causal relationships between latent constructs. The role of experiments is to measure these causal relationships and to adjudicate between theories by identifying cases where different theories make different predictions about particular relationships.
discussion questions
- Identify an influential theory in your field or sub-field. Can you draw the “nomological network” for it? What are the key constructs and how are they measured? Are the links between constructs just directional links or is there additional information about what type of relationship exists? Or does our description of a theory in this chapter not fit your example?
- Can you think of an experiment that falsified a theory in your area of psychology? To what extent is falsification possible for the kinds of theories that you are interested in studying?
readings
A fabulous introduction to issues in the philosophy of science can be found in: Godfrey-Smith, P. (2009). Theory and reality. University of Chicago Press.
Bayesian modeling has been very influential in cognitive science and neuroscience. A good introduction in cognitive science comes from: Lee, M. D. & Wagenmakers, E. J. (2013). Bayesian Cognitive Modeling: A Practical Course. Cambridge University Press. Much of the book is available free online at https://faculty.sites.uci.edu/mdlee/bgm/.
A recent introduction to Bayesian modeling with a neuroscience focus: Ma, W. J., Kording, K. P., & Goldreich, D. (2022). Bayesian models of perception and action: An introduction. MIT Press. Free online at https://www.cns.nyu.edu/malab/bayesianbook.html.
References
Block, Ned J, and Jerry A Fodor. 1972. “What Psychological States Are Not.” The Philosophical Review 81 (2): 159–81.
Bronfenbrenner, Urie. 1992. Ecological Systems Theory. Jessica Kingsley Publishers.
Clarke, Edward H. 1884. Sex in Education: Or, a Fair Chance for the Girl. Boston: Houghton, Mifflin; Company.
Cronbach, L J, and P E Meehl. 1955. “Construct Validity in Psychological Tests.” Psychol. Bull. 52 (4): 281–302.
Ellwood-Lowe, Monica E, Ruthe Foushee, and Mahesh Srinivasan. 2022. “What Causes the Word Gap? Financial Concerns May Systematically Suppress Child-Directed Speech.” Developmental Science 25 (1): e13151.
Elman, Jeffrey L, Elizabeth A Bates, and Mark H Johnson. 1996. Rethinking Innateness: A Connectionist Perspective on Development. Vol. 10. MIT press.
Fried, Eiko I. 2020. “Lack of Theory Building and Testing Impedes Progress in the Factor and Network Literature.” Psychological Inquiry 31 (4): 271–88.
Goodman, Noah D, Joshua B. Tenenbaum, and The ProbMods Contributors. 2016. “Probabilistic Models of Cognition.” https://probmods.org/.
Guest, Olivia, and Andrea E Martin. 2021. “How Computational Modeling Can Force Theory Building in Psychological Science.” Perspectives on Psychological Science 16 (4): 789–802.
Harris, Richard J. 1976. “The Uncertain Connection Between Verbal Theories and Research Hypotheses in Social Psychology.” Journal of Experimental Social Psychology 12 (2): 210–19.
Hempel, Carl G. 1952. “Fundamentals of Concept Formation in Empirical Science, Vol. Ii. No. 7.”
Killingsworth, Matthew A, Daniel Kahneman, and Barbara Mellers. 2023. “Income and Emotional Well-Being: A Conflict Resolved.” Proceedings of the National Academy of Sciences 120 (10): e2208661120.
Kraus, Michael W, Ivuoma N Onyeador, Natalie M Daumeyer, Julian M Rucker, and Jennifer A Richeson. 2019. “The Misperception of Racial Economic Inequality.” Perspectives on Psychological Science 14 (6): 899–921.
Kuhn, Thomas. 1962. The Structure of Scientific Revolutions. Princeton University Press.
Lakatos, Imre. 1976. “Falsification and the Methodology of Scientific Research Programmes.” In Can Theories Be Refuted?, 205–59. Springer.
Lindley, Dennis V. 1956. “On a Measure of the Information Provided by an Experiment.” The Annals of Mathematical Statistics, 986–1005.
Meehl, Paul E. 1978. “Theoretical Risks and Tabular Asterisks: Sir Karl, Sir Ronald, and the Slow Progress of Soft Psychology.” J. Consult. Clin. Psychol. 46 (4): 806–34.
———. 1990. “Why Summaries of Research on Psychological Theories Are Often Uninterpretable.” Psychological Reports 66 (1): 195–244.
Myung, Jay I, Daniel R Cavagnaro, and Mark A Pitt. 2013. “A Tutorial on Adaptive Design Optimization.” Journal of Mathematical Psychology 57 (3-4): 53–67.
Oberauer, Klaus, and Stephan Lewandowsky. 2019. “Addressing the Theory Crisis in Psychology.” Psychonomic Bulletin & Review 26 (5): 1596–1618.
Ouyang, Long, Michael Henry Tessler, Daniel Ly, and Noah D Goodman. 2018. “Webppl-Oed: A Practical Optimal Experiment Design System.” In CogSci.
Roberts, Seth, and Harold Pashler. 2000. “How Persuasive Is a Good Fit? A Comment on Theory Testing.” Psychological Review 107 (2): 358.
Rohrer, Julia M. 2018. “Thinking Clearly about Correlations and Causation: Graphical Causal Models for Observational Data.” Advances in Methods and Practices in Psychological Science 1 (1): 27–42.
Sandvik, Ed, Ed Diener, and Larry Seidlitz. 1993. “Subjective Well-Being: The Convergence and Stability of Self-Report and Non-Self-Report Measures.” Journal of Personality 61 (3): 317–42.
Shepard, Roger N. 1987. “Toward a Universal Law of Generalization for Psychological Science.” Science 237 (4820): 1317–23.
Smaldino, Paul E. 2020. “How to Translate a Verbal Theory into a Formal Model.” Social Psychology.
Sprenger, Jan, and Stephan Hartmann. 2019. Bayesian Philosophy of Science. Oxford University Press.
Strevens, Michael. 2006. “The Bayesian Approach to the Philosophy of Science.”
Tenenbaum, Joshua B. 2000. “Rules and Similarity in Concept Learning.” Advances in Neural Information Processing Systems 12: 59–65.
Ungar, Michael. 2002. “A Deeper, More Social Ecological Social Work Practice.” Social Service Review 76 (3): 480–97.
Wigner, Eugene P. 1990. “The Unreasonable Effectiveness of Mathematics in the Natural Sciences.” In Mathematics and Science, 291–306. World Scientific.